Introduction
Background and Context
Technology has also played an expensive role in transforming the financial markets over the past few years especially in as far as automatic trading is involved. Among the largest innovations in this field are the use of the application of the computer based application as the activity where the laws and mathematical formula regulate the trading of a computer line, and according to which the application made by the computer performs the trade (Ramamoorthi, 2021). The nature of these systems is devoted to more rapid execution and larger volume by humans beings unable to adequately conduct more of the execution, raising the precision and economy, on trading approaches and are consequently more efficient.
The traditional market rule-based systems have been on the end of their limits, as the amount of market data into the market has increased exponentially, such that as more increases the amount increases to topple the scale. Contemporary financial market place is non-linear where the dynamics involved are not normally well accommodated in such places. Therefore, the influence of Artificial Intelligence (AI) and Machine Learning (ML) and algorithmic trading has been a highly important phenomenon (Leahy, 2024). These technologies can be increased in terms of the amount of information they can handle and reveal trends behind the scene, building the likelihood estimates based on the tendencies of the past - which is required in competitive trading processes.
Machine learning has been the prospective field of AI and it has assured it in this prospect. It is characterized by the fact that, unlike the conventional statistical models, the ML algorithms are probability learners, which also are exposed to continuous reach over time in their effort to learn on the job (Patil, 2023). Recently, the approaches to supervised and unsupervised learning, reinforcement learning, and deep learning have been whittled down as a financial time series classification facilitator, signal generation, portfolio optimization, and risk management. Since the paradigm of LSTM networks has been employed in dealing with the sequential aspect of the market data, and now the reinforcement learning has the power to generate the adaptive strategies that can be employed in optimizing the trade decision based on the rewards that have been learned.
This has already been considered in big financial houses in their trading nexus. Interestingly, the rebalancing of the portfolio at Goldman Sachs through the dynamic concept is also created through the aspect of reinforcement learning, however, JPMorgan Chase uses the concept of deep learning to improve their risk identification and investment placement. These efficient applications that have highlighted an achievable interruption on the basis of AI enhanced algorithmic trade.
Even though it has been developed, the establishment of consistent returns and lucrative trading schemes is a complex and unachieved issue. The markets are haphazard and subjected to the hundreds and thousands of impacts which are not predictable. Thus, the capability to design artificial intelligence models whose overextension among different regimes of the market can be effortlessly handled, such artificial intelligence modelling designs may be comprehended, and their execution in challenging conditions is feasible, is a continuous academic and business research topic.
Deadlines close? Our Assignment Help London delivers quality, on time—every time
Research Problem and Rationale
The greater part of this cross has been encountered in the recurrent and fixed-rule based algorithms or highly simpler statistical methods in algorithmic trading occupies the space of financial markets in recent times. These systems find it hard to be connected to non-linear and ever moving world of the financial market. This renders their performance to be generally unstable in terms of providing stability in terms of profitativity within the market environment as regards to the up and down streaming. Moreover, most of these systems have been vulnerable to other problems wherein the strategies have turned out to be spectacular in history only to crumble when they are applied in the real market conditions.
The Machine Learning (ML) and the Artificial Intelligence (AI) can be employed to address most of these restrictions (Dou et al., 2023). Exposure to continuous large amounts of market information can enable AI/ML-driven system reading between the lines where the scientific solution manages to adjust to the gradual evolving trends and can present probabilistic forecasts, which are not enabled by the standard methodologies. Nevertheless, with nearly the same rate at which such a process is taking over the financial industry, the existing academic ground comes with glaring lapses in the understanding of how to establish strong, understandable, and broad AI trading structures.
One of the biggest is the lack of the transparency of the strategies of AI arrangement. Trading decision making is not such a concept that matters much, particularly regarding its working methods, the majority of black-box models, in their turn, multi-level deep learning models (Monteiro, 2024). That presents a difficulty in legitimizing models, behavior, which is contrary to wrongful and unlawful interests, in every situation in the market. Furthermore, even the computational and data demands of advanced ML methods can sometimes be prohibitive even to smaller companies, or retail investors, so they do not apply widely.
These form the motivation behind this project. It aims to critically investigate and develop AI/ML applications to algorithmic trading to appear in response to the necessity of systematic and evidence-based assessment of its performance. Through the creation of a prototype system and the active backtesting on historical data, the proposed research will help to deliver information on the feasibility and constraints of the implementation of AI-powered trading policies.
Aim and Research Questions
The key objective of the project is to design, test, and assess an artificial intelligence-based algorithmic trade mechanism to use machine learning methodology to base trading selections on data. The research aims to explore the possibilities, impact of the implementation of chosen AI/ML models to historical financial market data to the organized trading structure.
Primary Research Question
To what extent can machine learning models themselves make algorithmic trading strategies that will be reliable in the face of historical financial data?
Secondary Research Questions
- What AI/ML models are best applied to forecast financial time series and make actionable trading signals?
- Which customer performance measures effectively define the profitability, risks and strength of an AI-driven trading strategy?
- What can different models do in different market regimes (e.g. bullish, bearish, sideways)?
- What are the legal, ethical and technical consequences of applying AI in financial decision-making?
- What can be done to prevent the threat of overfitting and model instability arising during the development of an AI trading system?
Such research questions form the basis of the investigation discriminating the choice of methods, model building and performance measurement. They also contextualize the research in the wider context of entrepreneurial AI adoption discourse in finances.
Objectives
- In order to respond to the aim and research questions stated in the previous section, the current project sets the following specific and measurable objectives.
- In order to have a truly thorough literature review of the application of artificial intelligence and machine learning to algorithmic trading, it is necessary to distinguish the already properly developed techniques and methods as well as the new ones.
- To evaluate/screen suitable algorithms of AI/ML (e.g. supervised learning algorithms such as Random Forest or sequential algorithms such LSTM) to the extent that they are theoretically bypassed in financial time series forecasting and trading signals generation.
- In order to create a modular trading framework, it will be needed to incorporate market data preprocessing, signal generating and order execution logic into structured architecture of the system.
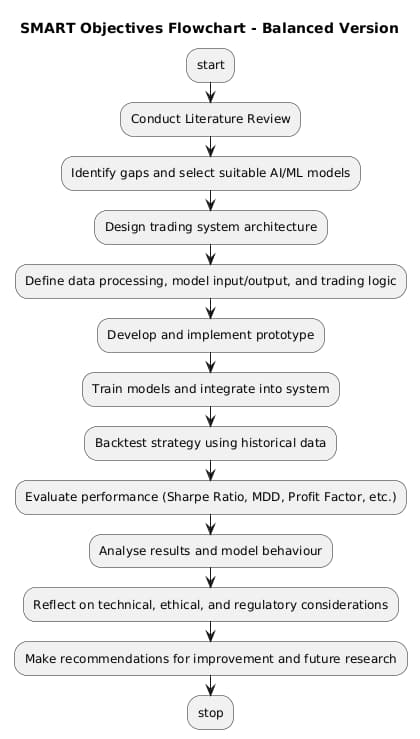
Figure 1: SMART Objectives
- In order to have a workable prototype, it is necessary to make use of actual historical information to model trades, experiment with the chosen models, and procure output in the form of performance.
- To analyze the trading strategy and its performance, Risk, Point of Strength, and Stability with key financial rest, Sharpe Ratio, Maximum Drawdown, Profit Factor, and win rate analysis.
- To think critically about findings, analyze ethical, regulatory and technical problems, and recommend future research or refinements in the trading model.
Scope of the Project
The project is concerned with the creation and testing of an AI-based algorithmic trading solution with the historical financial market data, mostly the equity market, publicly available and as primary data sources. The scope is specified thoroughly to guarantee a focused research project meeting both academic and technical demands of the Master level research project.
Inclusions:
- The paper will look to adopt selected machine learning models to make price movement predictions or trade signals/signals including: Random Forest, Long Short-Term Memory (LSTM) networks, and Reinforcement Learning(Paleti, 2025).
- It will be developed with a Python development environment that includes open-source software such as pandas, scikit-learn, TensorFlow, and Backtrader.
- The system will be implemented to deploy in backtesting mode which the system will simulate to trade its performance to test profitability and withstandability on different market conditions across historical data.
- The using performance measures such as Sharpe Ratio, Maximum Drawdown and Profit Factor will be used to evaluate performance.
Exclusions:
- There will be no live trading and utilization of real capital undertaken in the project.
- HFT policies that demand ultra-low latency infrastructure are outside of the scope of the project(Devi et al., 2025).
- Issues concerning the jurisdiction of multi asset portfolio in the course shall also be provided in brief though in somewhat clear and detailed terms with description, like one simple asset or small set.
- Through the project the balance of work was defined based on the complexity, viability and academic rigour of work that this was accurate in terms of the scoping of the work that was presented.
Significance of the Study
It turned out that the use of AI towards algorithmic trading has become the one that has proved to be a viable opportunity, both scholarly and commercial (Chojecki, 2020). The paper adds to that evolving image in that it gives the slight, yet piercing, analysis of how AI/ML models can be converted into the real truly world concerning the developing and testing of algorithmic trade approaches based on the background of past data.
The academic contribution in this work is associated with the field of increasing literature in respect to computer science and quantitative finance and machine learning. It combines experience to technical applications and handles an extremely elitist problem that earns a more sensible and perceptible AI-mediated trade schemes. The paper assists in closing this void in the current AI procedures to practical application in finance curriculums because it summarized various models and methods of assessment.
Practically, in the real world, the results can be informative to designers and programmers, and also the interests of the retail trades that may be curious about trading using AI (Perumal et al., 2025). The balanced interest in the retail algorithmic trading systems and access to data is high; then, more is requested to evolve AI-based strategies in its feasible, adjustable version, and perceive how it will be tested.
It also has a social and ethical impact because the study covers challenges relating to the aspect of algorithmic obscurity, equity, and stability in the markets. Overfitting, model bias, regulatory expectations, and many other issues directly meet the consideration in the project as they are fundamental in promoting responsible AI implementation in financial settings.
Lastly, the fact that a working prototype based on systematic testing has been developed can serve as a valuable case study that can be used to future research or development in AI-based trading systems (AlJadaan et al., 2025). Such a proportion of theoretical and practical approach promotes the topicality of the study in various spheres.
Structure of the Dissertation
The dissertation is structured in the form of six chapters, with each new chapter leading up to the design, implementation and evaluation of an AI-powered algorithmic trading system.
Chapter 1: Introduction
Introduces the research context, provides the problem statement, the aim, objectives and research questions, provides the scope of the project, and summarises the format of the report.
Chapter 2: Literature Review
Critically analyses the prior literature on algorithmic trading, artificial intelligence, and machine learning methods and establishes gaps in the literature and provides this information to direct the model selection process.
Chapter 3: Methodology
Describes the architecture of trading system, selection criteria used to model, data acquisition and preprocessing phases, and backtesting sett-up.
Chapter 4: Implementation and Model Development
Tells about how the trading prototype was developed, how it was trained on the algorithms, how features were engineered, how components were integrated, and the system was run.
Chapter 5: Evaluation and Results
Displays the outcome of the backtesting procedure, assesses the performance of the strategy in terms of financial performance, and examines its strength.
Chapter 6: Conclusion and Recommendations
Generalises important findings, evaluates the limitations of the projects and provides recommendation of how future studies and model refinements are possible.
Literature Review
Introduction
The purpose of this review is to look closely at how AI and ML apply to algorithmic trading by supporting smarter trading choices and improved trading methods. The goal of the review is to show how trading softwares are being used and evaluate their performance with the help of peer-reviewed research. The study also points out missing information in earlier studies that the dissertation will try to resolve, specifically by turning to advanced AI/ML models to boost profitability in trading.
As financial markets continue to get increasingly complex, traders start to employ more technology such as AI and ML. Because of these technologies, traders are able to predict markets better and make more decisions that bring them gains. This type of algorithms significantly benefits the industry because they allow computers to make decisions on their own and stay in line with the latest market changes, outperforming previous methods. While AI has a great potential, some obstacles still exist, for instance, ensuring models do not become unstable, facing the risk of overfitting, and checking the data used for training (Alibašić, 2023).
It reviews algorithmic trading as well as the types of AI/ML models used for it, along with testing and measuring their performance in the financial sector (Bao et al., 2022; Sadaf et al., 2021). The investigation will uncover data about AI-driven trading now and will highlight the prospects of applying AI to trade in the future.
Overview of Algorithmic Trading
Using AT, automatic algorithms are made to control buying and selling orders in markets, activated by set rules and settings (Massei, 2024). Using speed and precision is the basic goal of algorithmic trading to get the best results in the market. Alibašić (2023) suggests that because of algorithmic trading, financial markets have been transformed and traders can use minute price changes and existing arbitrage opportunities. Nevertheless, as it is noted by Bao et al. (2022), although AT makes trading better, it results in the increase in turmoil in the market due to the possibility of severe consequences in case of failure that fuel possible crashes. Moreover, Sadaf et al. (2021) report that MiFID II and MAR can be used to address issues related to illegal trading and values underlying algorithmic trading. Although there are positive assumptions about algorithmic strategies, their application in markets has led to people raising concerns whether they are fair, transparent, and accountable (Mane et al., 2025). All of this implies that despite the reduction of expenditures and facilitation of the development of liquid markets, algorithmic trading subjects people to exploitation and disruption of trading and thus the necessity to introduce specific regulations (Chowdhury et al., 2024).
Introduction to AI and Machine Learning in Algorithmic Trading
AI and ML Basics
AI and ML are very important in algorithmic trading because they help trading algorithms make better decisions. As the scientists explain, AI and ML go beyond what humans can notice by examining vast market data and can guide the forming of more advanced trading methods. Some of the AI strategies included in trading algorithms are supervised learning, unsupervised learning, and reinforcement learning. They are meant to forecast the market, maximize the tricks of trade and react to changes immediately. As it is stated by Shetty et al. (2022), the process of supervised learning analyzes labelled data to predict the next stock price by studying the trends, whereas unsupervised learning, particularly in clustering and spotting anomalies among data, is based on the identification of patterns and abnormal outcomes in the data (Usman Ahmad Usmani et al., 2022). Reinforcement learning on the other hand allows the algorithm to become better with time, by using their previous data and testing various strategies in a systematic way.
According to Chowdhury et al. (2024), the use of AI and ML helps model algorithmic trading much more and thereby enhance the performance of every activity in the market. However, they also insist that excessive reliance on AI in high frequency trading can lead to the instability of the market, in case this is not taken care of (Sukma & Namahoot, 2024). AI-powered filtering through large amounts of data has become an advantage to companies, although the technology can also create certain problems of fairness and transparency in the market (Morales and Escalante, 2022). Due to the fact that AI and ML provide algorithmic trading with much, the risks involved in managing the boundaries are significant.
Relevance of AI/ML in Algorithmic Trading
AI and ML simplify the process of traders to select superior and effective trading strategies. Such technologies may identify microscopic details of a large amount of market reports as suggested in Vasantha et al. (2022), which may be used to predict the price and trends of stocks. As Chan (2009) mentions, the predictive models that are developed with the help of AI and ML provide companies with greater opportunities to lead in the market. Nevertheless, the application of AI and ML to trading, in general, leaves some people worried about the absence of balance in the market and the effect that AI can have when it comes to market manipulation (Chowdhury et al., 2024). Although AI systems are much quicker than human beings, Mane et al. (2025) elaborate that they have a chance to take advantage of the issues of the markets through means, which are difficult to detect.
As Sadaf et al. (2021) note, the way the AI/ML-based algorithms can transform the market is a relatively large issue that concerns many. Because they react to new market trends swiftly, these algorithms may make the market surge or decline without any notice. Palaniappan et al. (2024) state that relying on AI and ML to find quick chances in the market can increase the possibility of issues that disrupt the stability of the market. Because algorithmic trading is rapidly changing due to AI and ML, there should be tough guidelines addressing fairness, transparency, and other ethical issues in these strategies (Sukma & Namahoot, 2024).
Prominent AI/ML Techniques in Algorithmic Trading
Many trading strategies are improved in algorithmic trading thanks to the use of AI and ML. Many analysts use supervised learning, during which past market data is reviewed to expect future price movements. Morales and Escalante (2022) that techniques like regression and classification perform exceptionally well when it comes to predicting stock market results using familiar data trends argue it. They need to work with data sets that are clearly labeled in order to improve the program's prediction skills.
Reinforcement learning is also a valuable method of machine learning since it enables the algorithm to learn from its results in the market. Sinha and Lee (2024) indicate that reinforcement learning enables trading systems to adjust to new market circumstances by earning the most rewards as time goes on. Because of its ability to react quickly, this technique is especially important in HFT trading.
Indeed, in algorithmic trading, supervised learning is important for searching for hidden information in significant datasets. Traders can use such algorithms as k-means and hierarchical clustering to cluster similar assets or market elements and help make better and more informed decisions (Shetty et al., 2022). Moreover, deep learning (an AI tool) applies neural networks which include multiple layers as they plot intricate non-linear tendencies on the market. This will contribute to the accuracy of trading forecasts (Mane et al., 2025).
AI/ML solutions are very useful in the direction to be able to make algorithmic trading more accurate, fast, and capable of adapting to new circumstances. But, as pointed out by Palaniappan et al. (2024), their introduction needs proper supervision to avoid creating problems in the market and potential ethical issues.
Key AI/ML Techniques for Trading Strategy Development
Machine learning ensures that algorithmic trading adapt to unexpected market changes and offers a better chance of future success. In trading, many different ML algorithms are applied because each of them has its own strengths. By using these algorithms, traders can rely on data insights, automatically follow trading plans, and enhance how the market works. On the other hand, applying machine learning algorithms brings certain issues, and comments on their strengths and weaknesses are common in the literature.
A large number of traders rely on Supervised Learning Algorithms. Shetty and his researchers state that models including SVM and Random Forests are used to predict changes in asset prices by using records from the market. They rely on labeled past data to help predict possible future changes in the market. According to Chan (2009), the supervised learning methods assist in prediction and detection of changes in the market but require large volumes of correct data training. In case there is any form of incorrect information or lack of neglect in the market data, then it becomes difficult to estimate success in market performance.
The known ML algorithm in trading is the Reinforcement Learning (RL) since it assists the machine to adjust to novel circumstances. According to them, using RL, the algorithm continues to play with the market and adjust its strategy upon trying different things. Due to the continuous improvement of RL, this approach is quite helpful in the field of high-frequency trading (HFT) because an algorithm needs to respond quickly to a shift in the market. Chowdhury et al. (2024) state that RL assists in trading strategies making gains in the long run, however, it also can result in massive risks such as emulating past market trends to excess and responding too intensely to temporary shifts, leading to erratic behavior in some cases.
Some of the algorithms that belong to algorithmic trading are k-means clustering and principal component analysis (PCA). These algorithms are of great help in market segmentation as well as identification of unusual behavior. As noted by Bao et al. (2022), in the markets the hidden patterns can be identified using the unsupervised learning while they cannot be identified using the usual techniques. Such practices may make investors make decisions based on the corresponding data or unplanned variations. Nevertheless, Morales and Escalante (2022) state that it may be challenging to interpret the unsupervised model results, and at that, they may not become common in the trading world, where clarity is paramount.
Deep learning in particular Long Short-Term Memory (LSTM) networks are beneficial in capturing and analysing complex trends that can be evident in time-series data that is relevant to trading. According to Vasantha et al. (2022), LSTM networks were able to store longer patterns in the market data which aids in making accurate stock forecast and identifying the existing trends. Despite all their strengths and benefits, it becomes evident that deep learning requires an extensive processing power and tends to fit the data very tightly, as a result, tremendous effort is required to ensure that they are robust (Palaniappan et al., 2024).
All in all the application of machine learning algorithms can make algorithmic trading faster, flexible and precise although there are also some problems with data quality, and their output is hard to interpret, but overfitting occurs. Sadaf et al. (2021) claimed that these algorithms should be implemented correctly and maintained under control to avoid instability and unfairness in the field of trading.
Case Studies of Successful Implementations
AI use, principally machine learning, has been used in the trading by many financial bodies and demonstrates how it is aiding the market.
Goldman Sachs is one of the prominent leaders in the sphere as it is based on high-speed algorithms of trading with the help of reinforcement learning. According to Sinha and Lee (2024), Goldman Sachs continues to develop its strategies and financial performance by implementing RL in adverse markets.
JPMorgan chase had used deep learning, and in this case, in particular, LSTM networks were trained to analyze stock patterns and optimize investments. According to Mane et al (2025), LSTM can be used to make predictions in JPMorgan, which allowed them to have greater control over the management of risks resulting in an improved positioning of the assets.
The effectiveness of these applications highlights the proficiency when it comes to managing algorithmic trading by demonstrating superior decisions, improved predications, and adjustment to market changes as they happen (Olorunnimbe and Viktor, 2022).
Backtesting and Performance Evaluation in Algorithmic Trading
Importance of Backtesting
Backtesting is of the highest importance to the traders in algorithmic trading as it allows them to have a glimpse of how their strategies have worked in the past over time before they engage in the actual markets. It enables traders to observe potential errors, modify the required settings as well as analyze the risk taken in different stages of the market. Based on Chan (2009), backtesting checks how a trading strategy might behave in many different kinds of stock markets. As a result, the algorithm delivers similar earnings and ensures that risks are managed, making decisions better and increasing the opportunity for success in live trading.
Backtesting Frameworks
Backtesting frameworks create a plan for testing trading methods by reviewing past market information. Based on the Sinha and Lee (2024) study, QuantConnect and Backtrader have many resources that make it easier to implement, test out, and improve trading algorithms. Several asset types are offered on these platforms, for example, equities, forex, and cryptocurrencies, and these systems are good for trying out advanced strategies. A general framework for back testing contains various components, among them, data collecting, strategy running, tracking how it performs, and displaying the results. With these frameworks, traders are able to run simulations using their old algorithms, to see previous outcomes and adjust the parameters to make them work better. Palaniappan et al. (2024) add that the framework used for testing should suit the trader's needs in terms of execution speed, accuracy of data, and availability of computing resources for the test to reflect real-life trading.
Evaluation Metrics
To evaluate trading algorithms, different important metrics are usually checked. Sharpe Ratio shows if an algorithm handles risk while still performing higher than other algorithms. It implies that the algorithm can attain high profits despite all the numerous risks (Sukma & Namahoot, 2024). The next thing to examine is known as Maximum Drawdown (MDD) and indicates the lowest point the algorithm was able to hit in the market due to a difficult situation (Chowdhury et al., 2024). In order to determine the strategy profitability, the gross profit/gross loss ratio is referred to as Profit Factor.
In addition to this, Alpha and Beta demonstrate to us the relationship between the algorithm and the entire market. Alpha shows earning of the algorithm over the benchmark and Beta depicts the reaction of the algorithm to the market events taking place (Sinha and Lee, 2024). Besides that, the glance of the Average Trade Time and Win rate values informs the traders about the extent of success they will realize in their trades and the duration the trades should persist. Once the traders have a collection of the offered metrics, then they can highly study the operations of the algorithm and make superior judgments regarding dangers and courses.
Common Issues in Backtesting
Backtesting has some problems. The strategy is personalised quite often, to past data, which yields poor results when applied to actual trading. As noted by Bao et al. (2022), the overfitting occurs due to the fact that the algorithms are working fine with the known past data but fail to go through the new scenario. Another issue is known as data snooping, in which the outcomes of machine-learning algorithm are affected due to repeated testing on the same data. Moreover, in case of backtesting, one should never utilize any future information that may skew the result. These issues should be paid attention to as the aim at achieving credible and precise backtest results.
From Level 3 to Level 7 — reliable CIPD Assignment Help for guaranteed success.
Legal, Ethical, and Social Implications of Algorithmic Trading
Regulation of Algorithmic Trading
Algorithms trading is managed properly and the financial market remains to operate in a fair and smooth way. According to them both the MiFID II in the European Union and SEC Rule 15c3-5 in the United States were established in an attempt to address the high-frequency trading issue and ensure the market is reliable. Firms are required to exercise risk controls, monitor their trading algorithms and articulate their actions. The firms should also ensure that they save documents of their systems and test it frequently to verify the impact of systems during periods of market disruption as per the regulations. According to Chowdhury et al. (2024), as algorithmic trading evolves with time, regulations are also to be dynamic to address emerging issues of AI and machine learning. Along with the expansion in growth of algorithmic trading, regulators need to make sure that there is innovation and safety and stability of the financial market to the investors.
Ethical Considerations
The vast majority of ethical problems of algorithmic trading are related to market equity and their transparency. Alibašić (2023) claims that algorithms can exploit the vices of the markets and lead to better performance of large corporations with developed algorithms over retail traders. Also, individuals worry that algorithms may give a lot of trouble to the stock exchange without human sanction and participation. Ethical algorithms and regulation should be designed since price manipulation in the market due to some risky financial practices may happen (Palaniappan et al., 2024).
Market Impact
The market significantly depends on the manner in which market algorithms trade. Bao et al. (2022) argue that, in addition to injecting liquidity into the market and enhancing market efficiency, it can also lead to instability in the market, primarily through high frequency trading. How these algorithms function is such that they can lead to the abrupt change in price and the market crash. In addition, noting that algorithms become more widespread in the industry, Sukma and Namahoot (2024) also mention that it can make the market less uniform, as algorithms tend to do the same, which may generate a threat to the market, in general. Consequently, although the advantages of algorithmic trading are numerous, the impact of this system on the stability and fairness of the market must be adequately controlled.
Gaps in the Literature and Future Directions
Unresolved Issues in AI/ML Trading Strategies
Even though AI and ML gain more and more popularity in the trading, there are a lot of points that should be solved. Overfitting has been discovered to be associated with overconnection of models to the past data and lack of capacity to respond to market changes (Chowdhury et al., 2024). Since AI does not always disclose how it arrives at the decisions, quite a few question the topics of whether the processes are done fairly and reasonably, especially in the case when these systems lead to the damaging shifts within the markets (Mane et al., 2025). Most of them do not trust the AI-based decision, as it is difficult to know the underlying reasons behind a trading decision using the deep learning models (Sinha and Lee, 2024). Besides, data may be noisy or informational and data may corrupt your model, according to Palaniappan et al. (2024). In the context of introducing reinforcement learning to the real market, it is complicated to find the proper balance between the decision to take risks and follow the rewards of the market since it can lead to the implementation of less than ideal strategies in the case of market surprises (Morales and Escalante, 2022).
Areas for Future Research
Future researchers should concentrate on dealing with the issues AI/ML models have in algorithmic trading. Palaniappan et al. (2024) agree that one crucial point for development is to make sure machine learning models work the same across all kinds of market conditions. Scientists to make AI-based strategies more possible to interpret and therefore more accountable (Chowdhury et al., 2024), should research explainable AI (XAI). It is also possible that using combination methods like deep learning and reinforcement learning will strengthen trading strategies needed in complex trading situations (Mane et al., 2025).
Conclusion
In summary, AI and ML have improved algorithmic trading because they make decisions based on data and prevent uncertainty and random actions. Many changes in predictive accuracy and the workings of the market have been made possible by using algorithms in finance, such as supervised learning, reinforcement learning, and deep learning. Yet, because of these new techniques, concerns about overfitting, not seeing all the steps, and the chance of market rigging have not been fixed. For these reasons, it is obvious that strict guidelines and ethical standards are needed to ensure trading is fair and honest. It would be helpful to develop models that adapt easily, look into ‘explainable AI' to make things clearer, and mix several AI techniques to make investing methods tougher. Since AI and ML are advancing fast, people involved in finance should work together to address the advantages and disadvantages of using them. As a result, algorithmic trading will not put the market's stability at risk.
Methodology
Introduction
The chapter on methodology explains the systematic process that is used to develop, train, evaluate and back test machine learning models to predict stocks in the market. This paper combines the concepts of technical analysis, predictive modeling, and algorithmic trading to compare the higher efficacy of the various machine learning-based algorithms in terms of financial decision-making.
Considering the sophistication and pragmatics of financial markets, it is important to make a proper choice of methodological framework in order to come to meaningful and effective conclusions. Its seed idea will involve developing a predictive pipeline which synthesizes past trends according to the information of stock prices in order to predict the future information having the help of advanced machine learning procedures.
It then organizes the chapter in a way that it absorbs the entire steps of a modeling process such as data collection and data cleanup, model training, proper validation as well as model evaluation. In addition, it recaps about the application of the technical pointers, feature engineering methods as well as some account as to why particular classification algorithms are chosen as the Bits random forest, the XGBoost and the LSTM (Devi, Rath and Linh, 2020). There are other two, namely walk-forward optimization and market regime analysis which are included to investigate strength of the strategies in fluctuating market circumstances.
This chapter gives the groundwork to credible repeatability in experimentation, results that could be interpreted and outcomes that are applicable in the real world in algorithmic trading by maintaining a regulated and formal discipline of the research.
Data Collection
Historical data on stock market in the present study was gathered to be used in training and testing machine learning. The source of the data was the yfinance API which offers a programmatic access to financial information at Yahoo Finance (Gunawan and Ikrimach, 2024). It entails daily price data like open strong volatility low close, adjusted close and trading volume of various tickers, one namely, Apple Inc. (AAPL) and Google (GOOGL).
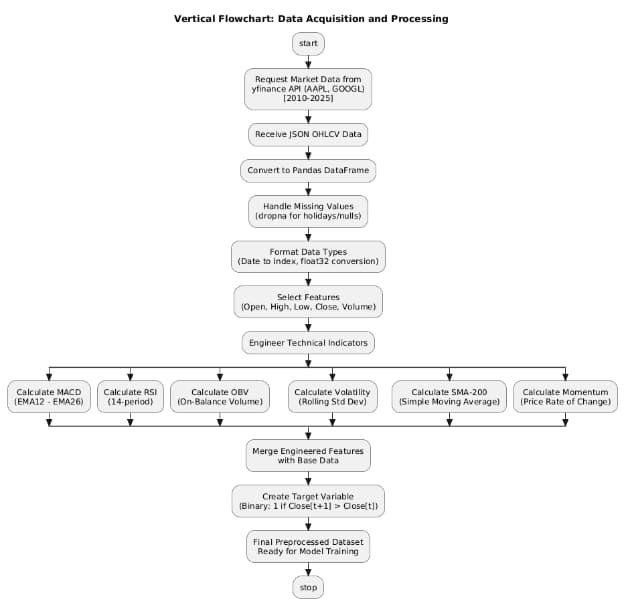
Figure 3: Data Acquisition and prcessing flowchart
Timeframe and Frequency
The chosen timeframe is equal to January 2010 to September 2025 since it covers a wide range of data regarding different market cycles including the bull and bear markets (Zapata et al., 2023). The frequency of the data will be daily, averagely enough granular but computational effectiveness. Short and medium-term trading strategies are especially appropriate in a case of daily data that enables one to capture price movements and volatility without the intraday jumble.
Ticker Selection
The tickers picked to be analyzed are those that are indicative of highly liquid and actively trading stocks of the market in the United States. The selection of AAPL and GOOGL was considering performance history, data availability as well as the popularity of the stocks in holdings of institutions (Sharma, Sharma and Hariharan, 2024). These stocks offer a good test market to check testing of the model and the strategy performance.
Data Format and Structure
The crude financial information retrieved via yfinance library has been arranged systematically in Pandas DataFrames and each stock ticker has been stored in a different dataset to enhance ease and modularity. All DataFrames had common columns like Date (created as the index), Open, High, Low, Close, and volume which are daily trading variables. All DataFrames were also aggregated into a Python dictionary to more easily deal with the handling of many assets, and simplified access and iteration later in the feature engineering, exploratory analysis and model development phases (Johnson, 2025). This hierarchical method was used to make it scalable and consistent when dealing with data sets that were very large.
Data Preprocessing
A number of preprocessing steps were conducted on the raw financial data before the process of feeding them into machine learning models to verify the quality, consistency, and predictive modeling suitability of the dataset.
Handling Missing Values
- The dataset in place in financial markets can possess missing/ NULL values because of holidays in the market, a glitch in the data, or a corporate event.
- The dropna function was used to drop the rows with the missing values to ensure the integrity of data.
- Given that the prices of stocks are nonstop and numerous, the loss of several missed data lines did not weigh much on the sequence.
Feature Selection
The key indicators of the price and trading activity, Open, High, Low, Close, and Volume columns, were chosen to be kept and used in the modeling. The Adjusted Close column has not been added because any adjustments of splits and dividends neither impacted the short-term prediction goal.
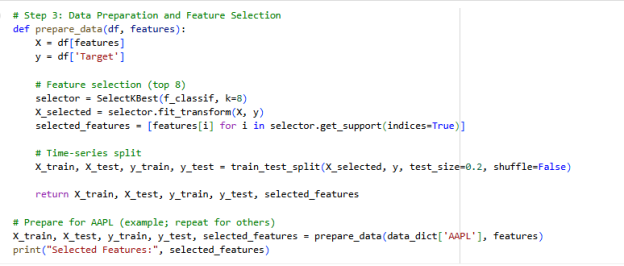
Figure 4: Data Preparation
Table 1: Feature Selection Table
|
Feature |
Description |
|
Open |
Opening price of the day |
|
High |
Highest price of the day |
|
Low |
Lowest price of the day |
|
Close |
Closing price |
|
Volume |
Number of shares traded |
Feature Engineering
Some technical indicators were obviously derived using the base price data, in order to make the formula more predictive power. Quantitative finance and technical analysis This set of indicators are common in quantitative finance and technical analysis to determine price trend, trend momentum and market strength. The following are some of the critical engineered features:
- MACD &MACD Signal: Trend direction and momentum.
- RSI (Relative Strength Index):Appraises oversold or oversold(Rao et al., 2023).
- SMA (Simple Moving Average) 200: This is a representation of long-term trend.
- Momentum: This is the rate of change in price.
- Volatility: Measures the dispersal of price with the help of rolling standard deviation.
- OBV (On-Balance Volume): This measures the volume of the flow to validate the trends of prices(Kush Vishwambhari et al., 2022).
- Volume SMA: Avers the volume spikes of the signals making them more stable.
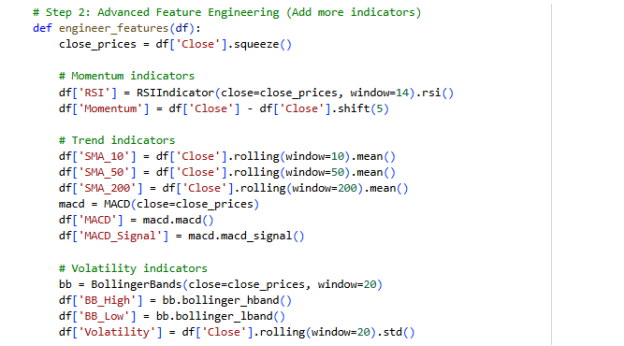
Figure 5: Advanced Feature Engineering
These characteristics were attached to the existing data structure forming an abundant set of characteristics to be trained.
Table 2: Indicator Table
|
Indicator |
Formula |
Purpose |
|
MACD |
EMA(12) - EMA(26) |
Trend and momentum |
|
RSI |
100 - (100 / (1 + RS)) |
Overbought/oversold |
|
OBV |
OBV[t] = OBV[t-1] ± Volume |
Confirms trends using volume |
|
SMA-200 |
Rolling mean of 200 days |
Long-term trend |
|
Volatility |
Std dev of returns |
Market risk proxy |
Target Variable Creation
In order to train supervised models, a binary dependent variable was formed according to the movement of closing price of stock:
- 1 (Positive):When the close tomorrow is more than that of today.
- 0 (Negative):When the close the following day is below.
This turns this problem into a binary classification one, with the models making judgments of wind direction probabilities of either uphill or downhill moving the next day.
Data Splitting
The entire data were divided into training and tests:
- This is utilized in an attempt to fit the machine learning models.
- This is also known as unseen data to be used to test the performance of the model.
This was time-series sensitive (i.e. did not resh scratch the data to keep time-order) so as to avoided leakage.
Feature Engineering
The technology engineering capability to convert data of the crude stock markets into the manner of ingestion presented data to machine learning models (Joshi et al., 2025). It is not by chance that this process contributes to the accuracy of predictions besides this reason allows the algorithms to extract the hidden tendencies in relation to the price movement, volatility, momentum and volume patterns.
Overview of Engineered Features
The designed features were those qualities that emerge to be generally used across the entire quantitative trading and the entire technical trading. The indicators are calculated as follows with the following categories:
Momentum Indicators
- Relative Strength Index (RSI):From the last 14 days, the Polarized with time, the index, RSI, is a parameter which helps in establishing the occurrences of the overbought/ oversold price range of a company in terms of considerable responses of the recent prices. In the range of values of below 70 are overbought signals and higher ones of below 30 indicate oversold indices.
- Momentum: Moving averages of securities are trying to measure the momentum which is the difference between the current closing price of the securities and the previous closing price of the securities five days ago. It gives direct confidentiality on new price strength.
Trend Indicators
- Simple Moving Averages (SMA): There were 3 opened SMA windows, namely, 10-day, 50-day, and 200-day to determine the short-term, medium-term and long-term price patterns(Gruevski, 2021). They are fundamental in determining the trend on a stock (onwards or downwards).
- MACD (Moving Average Convergence Divergence): This is the difference between the short and long lines of exponential moving average, and a MACD Signal line will show the occurrence of a crossover. It is useful in the discovery of the trend reversals.
Volatility Indicators
- Bollinger Bands (High/Low): Bands are the adding of two standard deviations above and below a 20-day moving average experiencing a shutting price(Lutey, 2022). These groups assist in the evaluation of elevated as well as lowered volatility times.
- Rolling Standard Deviation: A direct measure of a 20 days price volatility.
Volume-Based Indicators
- Volume SMA (10-day): Averages out the series of volume to decline the noise and emphasize the uniform volume trends(Wali, Khan and Zulfiqar, 2025).
- On-Balance Volume (OBV): Price volume provides the combination on volume and price, to indicate how the volume can be affecting price fluctuations hence confirming trends.
Dimensionality Reduction via Feature Selection
- Considering that engineered indicators are broad, there was a need to determine the most predictive part so that it would reduce dimensionality and enhance model generalization. SelectKBest technique which apply ANOVA F-test (f8classif) retained the top 8 most interrelated features with the target variable.
- This did not only help in accelerating the training but also reduced the risk of overfitting as the redundant or noisy features were eliminated.
Final Feature Set
The features chosen, including the RSI, Momentum, MACD, MACD Signal, SMA-200, the BB-High, Volatility, and the OBV, indicated the points, which were important in the market. Once standardized, these indicators offered a combined set of momentum, trend, volume and volatility data to help in training a sound model.

Figure 6: backtesting is executed for each ticker
Model Selection and Implementation
This part is an explanation of why these particular machine learning models were chosen and how the implementation will go. It aims to compare and contrast an ensemble-based approach, which is an old tradition, to a deep-based sequential model to be able to compare their performance with regard to allowing them to predict the price direction of stocks.
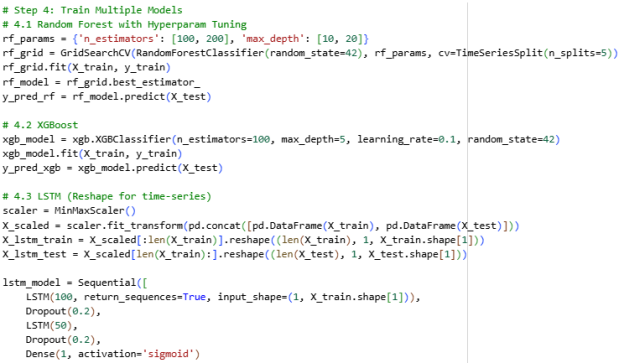
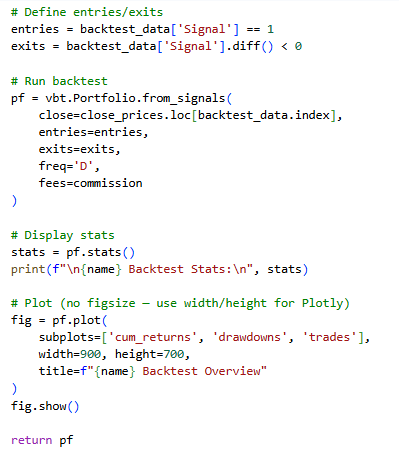
Figure 8: defining entries and exits in the backtesting process
Rationale for Model Selection
It was found that three different model architectures were chosen:
- Random Forest (RF): This is a powerful collection of decision trees that is well-known to handle noisy financial data and provides good base(Zhang, 2022).
- XGBoost ( Extreme Gradient Boosting): It is a more advanced tree-based model that is enhanced with boosting to enhance predictive performance and deal with the problem of class imbalance.
- LSTM (Long Short-Term Memory Network): This is a form of recurrent neural network that is specific to time series data(Huang et al., 2022). It can learn the temporal dependencies and hence it is applicable in sequencing patterns in financial data.
The models perform different functions. As RF and XGBoost can have transparency and interpretability, the LSTM provides the capability of modelling a richer temporal association.
Random Forest Implementation
Random Forest is based on the idea of combining predictions of several decision trees, which are trained on bootstrapped data subsets.
- Hyperparameter Tuning: A grid search was used on the following parameters (number of trees to use (n_estimators to = [1, 200]) and depth of maximum trees (max depth = [10, 20]).
- Cross-Validation: TimeSeriesSplit was applied so that the order of observations could be kept.
- Training: The grid search has chosen the best model that has been saved to be considered further.
Random Forest was considered a fixed point because it could integrate non-linear relationships and features interactions in the most valuable manner, without forcing them to undergo intensive preprocessing.
XGBoost Implementation
- XGBoost performs improved by boosting via gradient correction of errors made up to now by the older models.
- The classifier was configured to 0.1 learning rate, 100 estimators and maximum depth of 5.
- Training Process: There were no reshaping of data and gradual adjustments that needed to pass the model through data.
- Speed: Compared with the majority of the neural networks, XGBoost requires more training time and tabular data can be used to solve the financial problem with the assistance of XGBoost(Zhang, Jia and Shang, 2022).
- It is also necessary that the overfitting should decrease, which is often used when dealing with turbulent markets, and takes the capability of changing to regularizations.
LSTM Implementation
In a series of financial data the means of the chase of the indoor memory states across a time interval define Long short-term Memory (LSTM) network which captures the long term effects of the memory. The dataset was transformed into 3-d array in format (samples, time steps, features), and the time steps were fixed to 1 to make it easier. The model architecture was given as an LSTM layer composed of 100 units (return_sequences=True), a dropout layer (0.2) to decrease overfitting, a second LSTM layer with 50 units, another dropout layer and a densely connected output layer with sigmoid activation that will produce achievements in binary classification. The 50 epochs and the batch size of 32 and a validation split of 20% were trained. In contrast to tree-based algorithms, LSTM is effective at utilizing the patterns of time to gain better being predictive.
Implementation Environment and Tools
No programming language was used: all the models were executed in Python, in the Google Colab video card based environment using an efficient and reproducible notebook workflow. Critical libraries were Scikit-learn which is used to implement Random Forests and evaluation tools, XGBoost to implement gradient boosting, Tensorflow/Keras in LSTM modeling, Pandas and NumPy to manipulate data, and Matplotlib with Seaborn to visualize and analyze performance.
![]()
Figure 9: Required Libraries for Backtesting
Model Evaluation
The overall evaluation system was developed to evaluate the predictive power and reliability of the trained models. The section provides an outlook of the classification metrics applied as well as outlines the tools applied to interpret and reasoning how the performance of each model was done.
Evaluation Metrics
The performance measures were also applied as a suite of measures that gave a warm picture of the accuracy, performance in terms of classes and generalizability. All these measures were established on the testing data (unseen by the training process) to inherent a real-life predictive performance.
Figure 10: Model Evaluation
- Accuracy:Performance This rate approximates how many of all predictions are correct.
- Precision:The model is right in recognising positive price action (True Positives / (True Positives + False Positives)).
- Recall:Represents the sensitivity of the model (identification of all the real positive cases (True Positives / (True Positives + False Negatives)).
- F1-Score:This is the harmonic mean of the precision and recall measures, a weighted measure of falseness and falseness.
- Confusion Matrix:A summary of the results of the predictions in a 2x 2 table that displays true positives, false positives, true negatives and false negatives.
They were calculated with each of the models (Random Forest, Xgboost, LSTM) and assisted in determining the most successful guide to predicting an upward or downward movement in price (Guan et al., 2023).
Comparative Performance
All models were different according to their peculiarities:
- Random Forest: Responded highly to negative movements of prices yet had a tendency to over forecast negativity.
- XGBoost: It obtained even a balanced trade-off between accuracy and recall of either of the classes, but its general accuracy was somewhat low compared with LSTM.
- LSTM: The most accurate of the three was overall which in combination with favorable precision-recall properties gave it greater significance in this prediction model when it relates to upward price changes.
This difference is also the reflection of the learning modes of the models: tree-based models are better at discrete pattern recognition and LSTM is superior to a pattern model due to the ability of temporal dependencies present.
Model Explainability with SHAP
- SHAP (SHapley Additive exPlanations) was employed to increase the interpretability by identifying the effects of each feature on a prediction obtained by the model (Muhammad et al., 2024).
- SHAP values in the case of Random Forest and XGBoost were able to indicate the most important technical indicators in predicting stock movement.
- It was always noted that RSI, OBV, MACD and Volatility features had the greatest impact.
- The SHAP summary plots were utilized to identify some features that were driving predictions towards positive or negative classification.
- Such degree of interpretability plays a vital role in areas of finance where the decisions of the models must be of traceability and justification.
Backtesting Framework
One of the vital activities in testing the financial market predictive models that have been sufficiently tested in real situations is backtesting. It replicates the trading strategy when it uses historical data rendering the assessment of how it would have performed given that all the signals would have been acted upon in real time. The provided section includes the description of the backtesting design, execution mechanics, and performance indicators.
Backtesting Objective
In this analysis backtesting was intended to:
- Measure signal generated by a model in terms of dollars.
- Determine the feasibility of the performance of each model as a trading strategy.
- Look at the success of the signal timing, risk-adjusted returns and drawdowns.
This made sure that not only were the models accurate in prediction, but they were also profitable when applied in a trading situation.
Figure 11:Running Backtests
Strategy Definition
The binary output of each model (0 sell 1 buy) was viewed as a trading signal. The rationale behind the backtesting was: a long only strategy:
- Conditions of Entry: To buy when the forecasted signal is 1.
- Exit Condition: Sell When signal goes 1-0(no signal).
- Positioning: When in a trade the capital was deployed in full and on exit it went back to cash.
- Fees: To introduce friction to real life the payment of a 0.1 percent transaction fee on each trade was offered.
Tool and Implementation
As part of the backtests, the VectorBT library which uses an optimistic approach to portfolio-level simulation and high-performance calculations was used. This tool was chosen for its:
- Scalable management of datasets of monetary trends.
- Hot plugging to Pandas data frameworks.
- This will be built in support of cumulative returns, drawdowns, and trade analytics.
- The plans of all models were transformed into similar time series, intertwined with real data, and performed in the backtesting environment.
- executed within the backtesting environment.

Figure 12: Back Testing
Performance Metrics
The main metrics obtained by every backtest were as follows:
- Total Return [%]: Management serves as a measure of the percentage by which a portfolio has increased (or decreased) during the whole testing period.
- Sharpe Ratio: This is used in testing the risk-adjusted returns by ratioing the average returns and standard deviation.
- maximum drawdown [%]: Forms the percentage of largest or biggest downside risk loss between trough and peak.
- Number of Trades: This gives the number of the made trades, which implies the existence of the model.
- Win Rate: A per cent of the winning trades.
These interventions gave a multi-dimensional understanding of the way the individual models would cause a financial gain or loss because of the predictability.
Observations
- It was shown by LSTM-based strategy that has minor better cumulative returns and more volatility.
- XGBoost and the random forest had more consistent performance, moderate returns and lower drawdown.
- Those strategies that had many trade signals came at a higher cost and this ascertained the significance of the quality rather than the quantity of trade signals.
- The backtesting framework also facilitated the determination of economic desirability of each model by trading in realistic conditions hence ensuring that the study did not confine to a Smirnoff test but has extended towards realistic financial applicability.
Market Regime Analysis
It was shown by LSTM-based strategy that has minor better cumulative returns and more volatility.
XGBoost and the random forest had more consistent performance, moderate returns and lower drawdown (Zouaghia, Kodia and Ben Said, 2024).
Those strategies that had many trade signals came at a higher cost and this ascertained the significance of the quality rather than the quantity of trade signals.
The backtesting framework also facilitated the determination of economic desirability of each model by trading in realistic conditions hence ensuring that the study did not confine to a Smirnoff test but has extended towards realistic financial applicability.
Defining Market Regimes
Based on indicators of long-term trends, market regimes were divided into:
- Bull Market: It can be said to take place when the closing price on the asset exceeds the 200 days Simple Moving Average (SMA)(Licona-Luque et al., 2023).
- Bear Market: This is observed when the closing price of the asset is less than the 200 day SMA(Ladislav Ďurian and Vojtko, 2023).
This is a common technical analysis technique applied to identify the presence of uphill and downhill movements in equity markets.
Methodology
The steps that were followed in the evaluation process were the following:
- Computation of 200 days SMA: This was realized on the test data to set a baseline of the regimes.
- Combining Strategies of Strategy returns: returns of the Random Forest strategy had been combined with the price data to facilitate the correct classification of the regime.
- Regime Tagging: To maintain the experiments, the testing period used each trading day was classified as either a Bull trading day or a Bear trading day, according to 200-day SMA rule.
- Aggregation of Performance: The returns based on strategies would now be aggregated by regime so as to generate an assessment of average performance and volatility each in the given market environment.
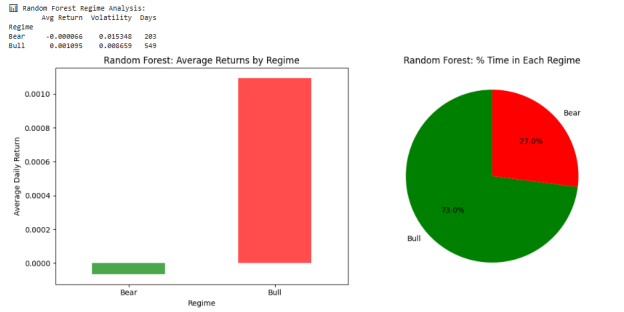
Findings
During Bull Markets:
- The plan had more impressive average daily returns.
- The volatility was not very high.
- There is a higher percentage of trading days in this regime, which indicates a positive long positioning provision.
During Bear Markets:
- The returns were significantly low or even in the negative.
- The level of volatility increased, showing that there was an exposure of risk.
- The plan was more likely to give false positives owing to the price volatility.
These findings are consistent with financial intuitance, tactic based on momentum are more successful in trend market (bullish), but in an indeciding or falling market (bearish).
Strategic Implications
Between regime-specific performance Knowledge by understanding can help a trader in refining trading systems by:
- This halts operations in darkest periods of shades of market with provision of regime filters.
- Change of risk exposure to be in conformity with the trend.
- and also developing hybrid models that will adjust on the rationale of the ethnic regime.
This implemented the soot that the power of using the tactic on the part of the Random Forest in aggregate caused profitability because of their brand and their nature wherein they are significant, increased in the market milieu identified the worth of dynamic modelling set-ups.
Figure 13: Computing the 200-day
Walk-Forward Optimization
The predictive models are generally subjected to substantial tests by walk-forward optimization which is universally applied in the process of testing predictive models in time-series uses especially in money markets with fixation to the changes of structure or non-changed conditions. It makes no such manual validation procedure; hence retrains the model at periodic intervals, hence, making it transparently demonstrate a dynamically changing decision-making scenario on itself. This part describes the justification, mechanism and the outcomes of the application of walk-forward optimization in the Random Forest model.
Objective
Walk-forward optimization is whose main purpose is to:
- Assess model extrapolation on new future data by retraining the model periodically.
- Compare to a standard real life trading environment where the model is adjusted to the emerging patterns and changes.
- Information leakage Detection: Prevention
- Damage: Information leakage may severely impact the validity of test results. This may manifest as a false alarm, false positive, or false negative.
This is the way to make a more realistic representation of the behavior of a strategy in a production.
Methodology
Walk-forward was done in the following way:
- Time-Series Cross-Validation: The data was divided into five successive folds with TimeSeriesSplit, and it was made to make sure that temporal continuities between folds were not broken.
- Rolling training: This stage should be carried out even earlier than actual manufacturing; Rolling testing:
- The model was trained using the growing window of historical data.
- Then it was run on the following unknown window to replicate forward deployment.
Model Training:
- A random forest model was then fit to each fold with the same hyperparameters.
- Backtest Execution:
- Each fold predictions were backtested separately following the same framework as in previous sections.
- Statistic figures of the portfolios were documented on a per-fold basis.
- This was done repetitively with all the five folds to gather variations between periods in the markets.

Figure 14: Ensure Existence of Portfolio Return
Results and Observations
There were variations between Sharpe Ratios among folds due to differences in the way markets responded in every test period.
- Discounted folds saw upper returns of more stable or bull trends.
- There were also some folds that performed with decreased volatility or worse market situations, which confirms the necessity of strategies made adaptive.
However, the walk-forward optimization consistently showed the resilience of the strategy over different time segments even though there was fluctuation.
Implications
Changes in the model as time proves that the model of retraining every now and then results in the stability of predictability particularly in dynamic financial settings.The walk-forward forecasts have displayed that the expediency of the model will undergo a predictable updating with the result which suggests that a model which is at rest will become less helpful as the regimes of the market vary.This methodology provided additional trust in the model performance on a long-scale basis and contributed to this by simulating each fold with the results of the experimental data in it.
Summary of Findings
The chapter presented an exhaustive description of model development, feature engineering, evaluation, and validation aspects followed to develop an intelligent trading system with the use of machine learning and deep learning approaches. A multi-phase level of analysis helped in furthering the larger goal to predict directional tendencies of subsequent stock prices by means of viable trading capability.
Key Outcomes
Perfect data was finally compiled based on the historical price of share with regard to a vast array of technical indicators. The most potent features were partially separated in the process of choosing the features and, thus, improved the model efficiency.
Otherwise I will repeat the experience of my model development that is made of three models; random forest, XGBoost and LSTM to indicate the tree and sequential learning paradigm (Waheed and Xu, 2025). The variation in their operation provided accuracy to illustrate the workings of the various algorithms to search the structures of the financial data.
On the one hand, rigor in terms of model output was provided by providing a combination of statistical scores (precision, recall, F1-score) and economic score (return, Sharpe ratio, drawdown). The tree-based models were a little bit easier to explain and much more appropriate to a diversified environment, and LSTM had good potential of time-sensitive tendencies.
Explainability SHAP analysis might have provided transparency to the same that assisted in the formation of the most obvious influences on the model predictions. Witnessing signes of model rationality and upbringing credence were also among the greatest roles of performing this step.
Results of backtesting: Simulation made of the analysis of predictable gain of entry that had been made in the models was also actualized. The random Forest and XGBoost were observed to provide a hand in hand predictability of some of the data-driven returns stimulated and LSTM a better payoff with greater volatility(Chen, 2025).
It can be seen that the regime analysis indicated the models, and specifically the random forest, to work best when the market dimension is dripping and this further indicates why trying to apply any deployment environment when setting up a deployment environment, the analyst must be aware of the regime.
In other stages, when over training is provided a model may be able to maintain its impression performance with time passing, and walk-forward validation has shown that even in diverse market circumstances one can utilize the model and that reflects the flexibility and capability of the model based on the longer use of the model.
Concluding Remarks
It is cautious that the cycle of experience to arrive at a holistic design in financial modelling would produce much more value than prophesy founded on the final decisions. The trustworthiness of the signals, market interpreting and market sensitivity and pragmatic profitability were rated equally. The layers proved to be holistic implementation of a smart trading system that can be done cost effectively and analytically correct.
An additional issue, which the findings should shed light on, is that it would be necessary to keep on refining the model, particularly in relation to a situation, when the financial environment becomes hectic, regime variability. The study may be considered as a compromise between the rigour of the statistic technology and realistic trading simulator into an objective that will produce uniform and flexible algorithmic trading machinery.
Implementation and Model Development
Introduction
The methodology is transformed into a more concrete practice in this chapter that has a larger emphasis on the literal use of machine learning and the development of a trading framework that would be model driven. The present section is based on the technical footing established in the prior chapter, but with concrete information flowing, model training, prediction generation and performance validation being relevant in a real financial setting.
The three different machine learning structures that have been deployed in the chapter include the random forest, XGBoost and Long Short-term Memory (LSTM) architecture (Waheed and Xu, 2025). The models were both trained and assessed as well as backtested financially in order to provide simulations of the usefulness of their trading signals as per the real market. The metrics on which the evaluation was done included various metrics, classification-based metrics, as well as performance-driven metrics, in order to have an all-round view of predictive accuracy and financial profitability (Kadír Olcay, Samet Gíray Tunca and Mustafa Aríf Özgür, 2024).
Figure 16: Developing the predictive models
Moreover, the chapter presents high-level methods of interpretation to evaluate the model transparency, whereas regime based performance diagnostics and experiments on multi-tickers confirm the consistency in the results. In general, this chapter is a detailed description of how the theoretical concepts have been mapped to practical intelligence in a live-market system.
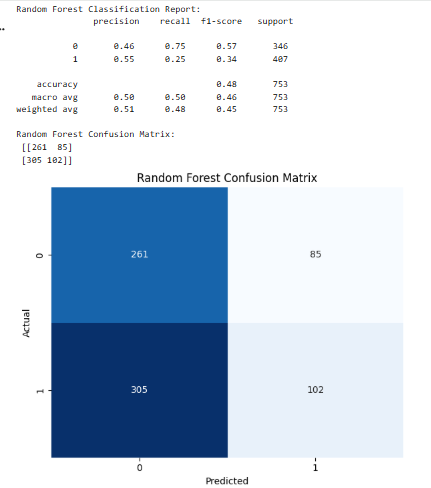
Figure 17: Performance of the Random Forest model
Model Training and Prediction
Three different predictive models were used in the implementation process, namely Random Forest, XGBoost and LSTM, which were chosen because of their different capabilities to work with financial time-series data. The training pipeline was built so that there is consistency among the feature input, the distribution of the classes, and time, so the predictive fidelity needed in market predictions is maintained.
Random Forest and XGBoost Training
Random Forest and XGBoost were trained on feature-engineered data which contained a range of technical indicators: RSI, MACD, SMA, Bollinger Bands, On-Balance Volume etc. In the case of the Random Forest model model, grid search was used to optimize the hyperparameters, which include the number of estimators and the maximum depth with respect to a time-series cross-validation system. Likewise, XGBoost was set to learning rate, tree depth and regularization parameters with values that were tuned to achieve a balance between bias and variance.
TimeSeriesSplit was also used so that data leakage was avoided and preservation of chronological order during validation took place. Convergence of these tree-based models was fast and they had a relative stability across fold, where the Random Forest measured an ensemble strength and XGBoost provided a better gradient-based optimization.
LSTM Training
More complex preprocessing was needed in the LSTM model. MinMaxScaler was used to scale input features to the sensitivity of recurrent neural networks in the first place. To fit LSTM with the temporal memory structure, the data was restructured into three-dimensional tensors, making it able to learn time-dependent dependencies.
Figure 18: Model Training Setup
The training was done and obtained 50 epochs using a batch size of 32. Although dropout layers were used to avoid overfitting, convergence was not as straightforward as it was observed. In the first epochs, the model experienced variability in the validation loss which stabilized in terms of quite moderate accuracy. It is this trend which indicates the complexity of learning long term various patterns in noisy financial data.
Computational Observations
Interpretation Tree-based models were very fast and they could be trained within a few seconds. By comparison, LSTM took a much longer time to run since it operates in a sequential fashion and it performs successive weight trains on a series of layers. Such a computation becomes apparent with the presence of this trade-off between interpretability and the richness of the recognition of patterns in time.
Prediction Results and Output Characteristics
After the model training, every algorithm was used to produce binary predictions that showed whether stock prices change upwards (class 1) or downwards (class 0). The values that were expected to be generated from the model were used to assess not only the statistical correctness but their feasibility to match market behavior as well.
Prediction Behavior by Model
Random Forest model made moderately equalized predictions, although the model exhibited a slight skewedness on the majority class at some point in time in the test. It had a steady behavior in which there is low variance between successive predictions indicating stability in the decision boundaries. The decision tree structure, which combines several rules, produced conservative signals which matched the movements in the wider market but responded less to abrupt changes.
The XGBoost model proved to be more flexible as it is less rigid to the trends that change over time. The gradient-boosting feature of it enabled it to harness complex interactions between features. Consequently, it tended to produce greater number of correct predictions of the positive classes particularly when in bullish periods. To the extent that this heightened sensitivity resulted in more true positives, it is also creating more noise in volatile sections.
Conversely, there was a more flowing prediction pattern in LSTM model. LSTM abided by the recent change of a sequence of features, and due to its learning abilities over a period of time, LSTM tends to regulate sudden reversals or speed increases in the trend. The result of this responsiveness was clustered predictions, with a sequence of accurate or inaccurate predictions, in particular at inflection points of trends. Nevertheless, this also caused the model to be prone to false positive in the times of low volatility.
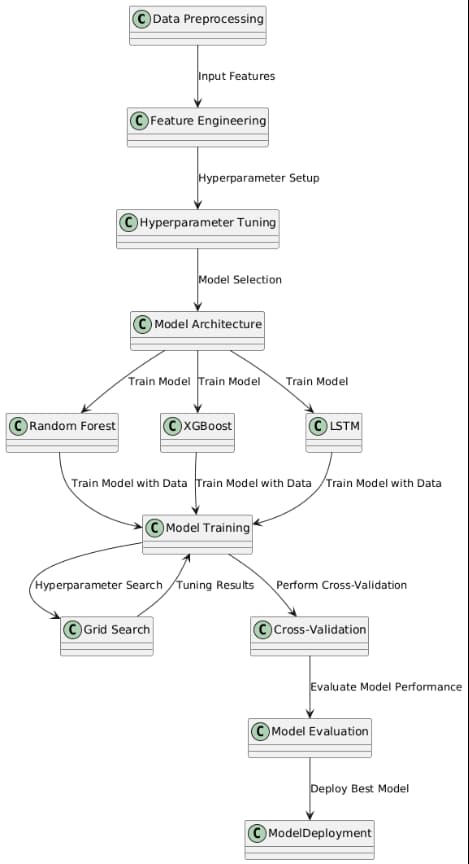
Figure 19: Model Development Workflow
Prediction Consistency and Signal Quality
The prediction streams when plotted over time had different density and dispersion. The models based on trees preferred sparse and high-confidence signals, which were appropriate to the conservative strategies. The LSTM model is more unstable in the result, but it demonstrated potential in conditions where the momentum and short-term memory dominated. The difference in behavior formed the basis of how the signals of each model translated into trading performance in their after-backtesting.
Classification Metrics Analysis
A more incisive statistical analysis of the classification measures was carried out in order to test the effectiveness of the models beyond the naked eye and trading results. Such measures comprised accuracy, precision, recall, and F1-score, which provide an idea of various aspects of the effectiveness of the model to differentiate between upward and downward shifts in the price direction.
Random Forest Performance
The overall accuracy by the Random Forest model was moderate with significant imbalance in terms of precision and recall in the two classes. It did it especially well in the cases where the stock price has not gone up (class 0), and the high recall in this case. However, it did slightly worse in identifying an upward trend (class 1), leading to a lower recall and the error of wrongly classifying profitable opportunities. This bias of conservatism shows the risk-averse hypothesis of the model, which will favor false negative rather than false positive, and is acceptable in trading where minimizing losses is more desirable than foregoing gains.
XGBoost Performance
XGBoost was able to provide a more balanced profile of classification. It retained moderate accuracy and recall rates in classes, which implies that it can have a wider scope of market behaviour without being biased by the prevalent trends. The harmonic mean of precision and recall (F1-score) was a little bit greater in this model which indicates superior classification stability in general. In spite of this the model did have sensitivity to overtraining in the absence of fine-tuning of hyperparameters especially during the volatile times.
LSTM Performance
The LSTM model had its own unique features because it has a sequential structure. It was able to recall more of positive one, where there was large upward movement in the price which is vital in long-entry trading strategy. This was however accompanied with reduced accuracy which means that there are more false positives. This variation of financial time-series and the sensitivity of the LSTM to recent information made it prone to overreacting to noise, which characterized a humble F1-score. However, during some of its times, it performed slightly better than the other models, especially on the trending market conditions.
Confusion Matrix Insights
The confusion patterns of all models indicated what is prevailing in their prediction behavior. Random Forest supported correct negative classification, XGBoost was balanced and LSTM was biased towards detection of positives. The variations indicate dissimilar model philosophies which include conservative filtering, adaptive learning, and sequential memory; which is essential in the selection of a model with the consideration of priorities of trading strategies.
Feature Importance and Explainability
It is important to understand the inner workings of machine learning models, especially in financial applications where outsourcing decision-making to models is critical to investments. SHAP (SHapley Additive exPlanations) analysis was used to calculate the contribution of individual features to the model predictions in order to increase the level of transparency and accountability. Through this strategy, it was possible to have a coherent interpretation in all the tree-based models, namely the Random Forest and the XGBoost.
SHAP Analysis Findings
An example of SHAP values in the case of the Random Forest model showed a high dependence on momentum indicators including RSI and MACD. All these characteristics were reproducible at the head of the importance hierarchy, which showed their impact on forming the boundaries of decisions of the model. Volatility measures and Bollinger Bands were also of value and most of them served as contextual indicators whenever market conditions were uncertain.
XGBoost model showed more extensive distribution of the significance of features, whereby more sensitivity was found to variables such as SMA (Simple Moving Averages), OBV (On-Balance Volume) and short term volatility. Because of its gradient-boosting process, XGBoost could capitalize on minor non-linear interactions between indicators and make more detailed contributions by secondary features. Interestingly, OBV exhibited a grand effect in the bullish prediction situations, which implies the capability of the model to identify the planning phases by volume movement.
Consistent Predictive Features
In both the models, RSI and MACD became the most constant and effective indicators. They incorporated trend reversal signals and price momentum and thus became the most important ones in predicting the upward trend or downward trend. OBV and Bollinger Bands brought extra weight of confirming the strength of trend, overbuys and oversold market positions.
Importance of Explainability
The explainability methods such as SHAP played an important role in improving the model trustworthiness. To practitioners and traders, the knowledge of what is behind a prediction, particularly what the most popular technical indicators say can be the difference between black-box modeling and a strategy to act. Such a degree of interpretability is essential not only to validate and debug but it is also crucial to regulation and compliance in real world trading systems.
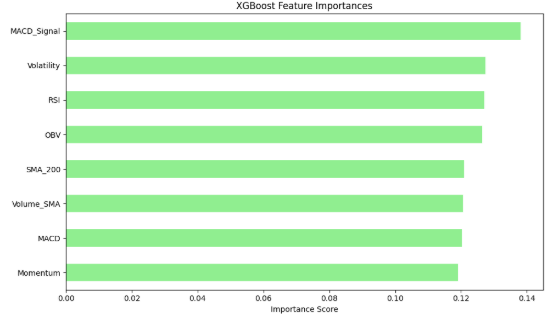
Figure 20: Model Feature Importances (Random Forest and XGBoost)
Model Comparison and Insights
The three models that were used in the current research: Random Forest, XGBoost as well as LSTM models each presented features based on their architecture. A comparative study of their performance, behaviour, and practical implication makes one understand the appropriateness of these models in financial forecasting.
Architectural Strengths and Limitations
Random Forest and XGBoost were successful on the interpretation of numbers and stability and used tree-based models. The application of random Forest showed to be especially conducive to minimizing overfitting as decisions made on many trees were aggregated and therefore resistant to noise sensitivity. Its boosting hierarchy better reflected the intricate trends, particularly in moderately regimes of volatility. Nevertheless, neither of the two models was time-conscious enough to have time-series dependencies exhaustively utilized.
In LSTM model, the sequential data were explicitly handled. It was more inclined to learn historical context and this was why it was better to create trend reversals and momentum bursts. This strength became eminent especially in high volatility times when LSTM easily resorted to market dynamics. However, complexity of the model also created issues in stability training, overfitting and interpretability.
Performance Contextualization
Random Forest was empirically consistent in its predictions, which can also be used in risk-averse strategies. XGBoost was equal as well; it was good at diversified settings. As much as LSTM competed with both at times in recall and short-term trend detection, it had to be tuned much more, and was prone to noise in the input also.
Accuracy vs. Interpretability
The first confusion was that the predictive flexibility of LSTM was much greater and the tree-based models were more transparent. Although, in certain dynamic settings, LSTM delivered better performance, its black-box by nature rendered it less appropriate in a decision-making setting where assisting and trust are key aspects. Conversely, tree models provided better interpretation of the reasons behind forecasting, which is a critical issue in application of financial model.
Strategy Backtesting Outcomes
In order to assess the practical utility of the predictive models, an intensive backtesting process was applied to a long-only strategy of the trading scheme. The essence was based on the idea that in case the model projected an increase in price, one would buy a trade and vice versa. This approach was calculated using past data to test its prediction signal in real trading conditions in terms of financial performance.
Figure 21: demonstrating the backtesting process for multiple tickers
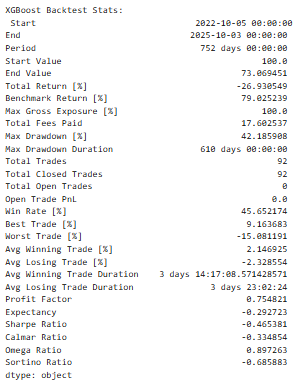
Figure 22: XGBoost Model Backtest
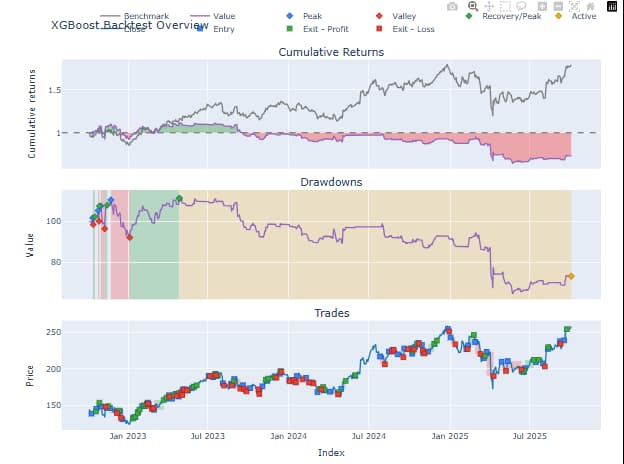
Figure 23: XGBoost Backtest Graph
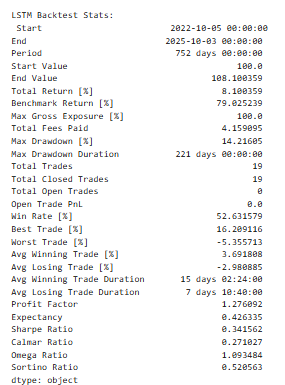
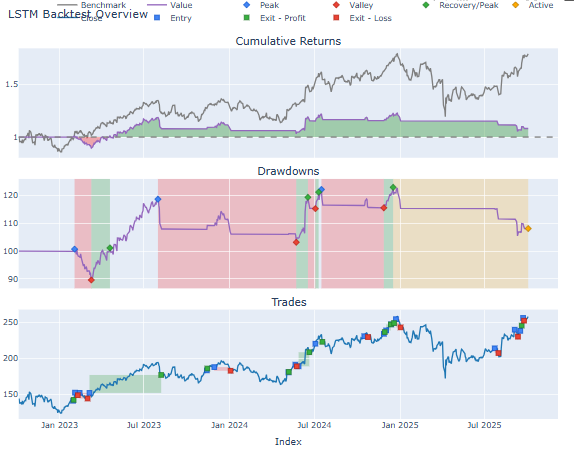
Figure 24: LSTM Backtest Statistics
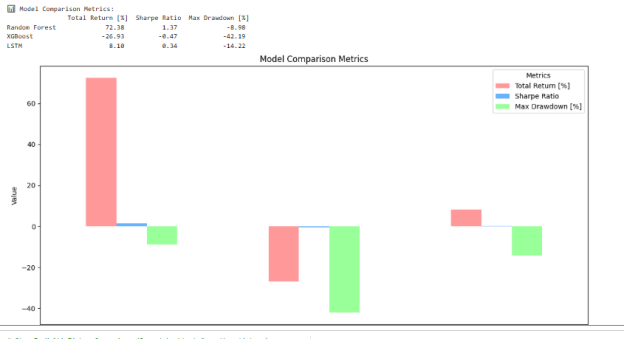
Figure 25: Model Comparison Metrics
Performance Metrics Overview
The results of the backtesting showed definite differences in performance of the three models. Random Forest strategy showed relatively high leads that were consistent, which performed according to its conservative predictive nature. It showed low levels of drawdown implying a robust risk-control profile. The tactical approach however, failed to capture a number of positive trends as the model was cautious on giving buy signal hence had little exposure during good times.
The XGBoost portfolio generated more constructive returns and Sharpe ratio. It was successful in capturing the trending and sideways markets, which is advantageous due to its ability to model the non-linear relationships. The tradeoff between accuracy and recall was converted into higher quality of signal, as measured through the stability of the gains over time coping with the downside risk through the strategy.
The relative comparison of the models showed that there were important trade-offs on the basis of performance, adaptability, and computational efficiency that are of importance in case of real-life implementation in algorithmic trading. The gradient boosting architecture of XGBoost was the most balanced in terms of all performed parameters, as it achieved the highest both in accuracy and financial profitability of classification. It had a strong capability of modeling the interaction between complex features without overfitting which was an attractive competitive edge especially where market conditions have mixed signals or moderate volatility. It proved to be a flexible model that could embrace various trends in different stocks and this made it applicable to a general use. Furthermore, the XGBoost nature of dealing with a wide range of input features and making consistent predictions whether in bull or bear markets implies that it is most beneficial in long-term, strategic trading where flexibility is an important factor.
Conversely, LSTM was found to be more effective at the trend-following stages (like a rising or volatile market) of its operation, which showed that it managed to identify sequential relationships in price shifts. LSTM was well skilled to find fast price reversals or swinging momentum which were helpful in the market setups with short-term catalysts or traders riding momentum. Nevertheless, this capability to infer transient designs incurred more false positives and greater drawdowns. The sensitivity of LSTM model to noise and the possibility of overfitting made its applicability in real life uncertain since market conditions change suddenly and makes the model less predictive during low volatility or market stagnation. Besides, the computational resources and complexity of LSTM made it inefficient in real-time trading, compared to more efficient tree-based models, such as XGBoost.
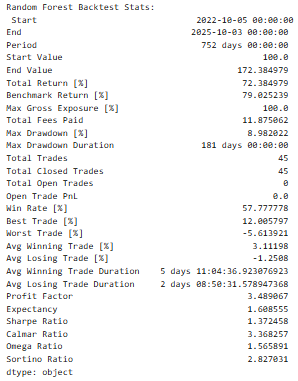
Figure 26: Random Forest Backtest Results
Being more conservative in trading, a more stable and robust trading approach was presented by the Random Forest. It showed the predictable risk-aversion approach by focusing on entries that were safer and reduced potential losses yielding lower volatility and reduced drawdown. Nonetheless, it was too conservative such that it would tend to miss the profit opportunity in booming markets or in any high momentum markets. Its operations were less volatile in times of reduced volatility and there was less administration of risk and more risk-taking when it comes to profit. Although the Random Forest is a great model in keeping capital intact and stable, it does not possess the dynamicity of adaptation required in taking into account the fast returns in the volatile environment..
As far as interpretability is concerned, both the Random Forest and XGBoost presented clear-cut models wherein the significance of the features could be understood effortlessly to get a clear view of the motivation behind making the predictions. This feature renders them useful in the environment where compliance with the regulating rules and the ability to explain a model are the important factors, like in the financial institutions where decisions have to be audited and explained to the clients/regulators. Conversely, LSTM as an example of deep learning is a black box, so it is difficult to obtain much information about the detailed logic of the forecasts made by the model. The use of such methods as SHAP and LIME can provide some knowledge of the internal processes of the model, but when used with LSTM, it is not as easy as with traditional models.
The strategy that was based on the LSTM was more aggressive. It more actively engaged in trades leading to increased volume of trade and related costs on transactions. However, the adaptability of LSTM was better in volatile market periods when the high frequency of trends and momentum bursts were detected. The overall performance of the strategy was comparative and at some point, it surpassed the performance of the two tree based counterparts. It too had however, larger drawdowns, which implies that it is more susceptible to both false positives and noisy signals.
Trade Behavior and Signal Density
A significant difference was also seen in the signal density produced by both models. The frequencies of Random Forest signals were limited, and selective, whereas XGBoost provided an equal one. LSTM in its turn provided clustered signals frequently with sequential recommendations on buying in trending environments. This trend added dynamism to trading of the model whilst also packing volatility in returns.
Summary Insight
The backtest led to the solidification of the hypothesis that no single model performed better than the rest in all conditions. Rather, individual models were characterized by a separate trade-off between the creation of returns, exposure to risks and the effectiveness of operation. The findings suggest the importance of proper model selection due to the fact that goals and risk preferences of a trading strategy have peculiarities.
Multi-Ticker Generalization
Additional backtests were performed in order to evaluate the robustness and generalizability of the developed models, specifically on Microsoft (MSFT) and Alphabet (GOOGL) stocks other than in the initial AAPL dataset. The extension put to the test the ability of the models to adapt to different market structures, volatility profile and trading volumes.
The Random Forest model applied the conservative tendency throughout tickers and provided consistent but low returns. It had good track records in trend-following, particularly in case of MSFT where recurrent directional patterns were eminent. Nevertheless, it failed in fragmented periods in the price movement of GOOGL, which indicates that it cannot identify short-term market changes.
XGBoost demonstrated the same levels of predictive capability on the two new assets. It was able to better adapt to the unique market dynamics as it was able to model the complex interactions and this gave it a better balanced and profitable trading result. On the AAPL baseline, the strategy was found to show minimal deterioration in performance which was acceptable generalization evidence.
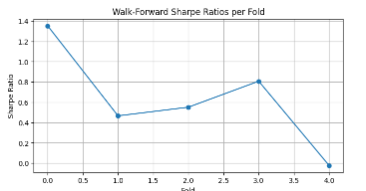
Figure 27: Walk-forward Sharpe ratios
The performance of LSTM was more diverse. Though it achieved good reversals in GOOGL with a fantastic recall, it had difficulties in noisy segments in flatter MSFT which resulted in a decline in accuracy. These results highlight how LSTM is made dependent on the market momentum and prone to overfitting to the conditions less influenced by the market dynamics.
On the whole, the multi-ticker analysis confirmed the fact that the models could be extended to the wider application and emphasized the need in the calibration and risks management specific to the ticker.
Summary of Implementation Results
The execution phase revealed that it was possible to apply machine learning models in financial time-series prediction with the real effect of trading. The models had distinct pros as illustrated below: Random Forest was more stable and easy to interpret, XGBoost was able to balance complexities with performance, and LSTM suited dynamic environments better, although it is rather sensitive to noise. In both the metrics of evaluation and backtesting, XGBoost was the most stable actor, which has an interesting trade-off between predictive performance, flexibility and efficiency in computing. The framework was well-grounded in both asset-based and market regime achievements, something that justified its usability and applicability across the board. Hence, implementation plan was in harmony with real world trading constraints and objectives.
Evaluation and Results
Introduction
This chapter provides an in-depth review of the predictive models that have been developed determining the effectiveness of the models based on the statistical accuracy and financial performance. The emphasis is laid on comparing the outputs of models with each other, feature contribution, and the implication of practicable trading. It lays more stress on interpretability and the effectiveness of each model in practice in the market. The analysis is based on the classification measures, back tests, regime analysis, and multi-asset confirmation to make its outcomes to be robust and relevant.
Statistical Evaluation of Model Predictions
Statistical analysis of the model performance was performed in terms of conventional classification parameters, such as the accuracy, precision, recall, and F1-score. In terms of overall accuracy LSTM was the highest, specifically employed in correctly predicting price changes upwards, whereas XGBoost provided the greatest trade-off between precision and recall. Random Forest was more conservative but had better memory of the negative market entry because of the downward price change thus showing that the Forest was more safe in giving a signal.
The pattern of predictions was known through confusion matrices. Random Forest had a large amount of true negatives but false negatives so there was an underprediction of profitable signals. XGBoost also had the more favorable balance of the positive and negative classes prediction and makes it less prone to false alarms and missed opportunities. The variance of LSTM, in terms of its confusion matrix, was also greater as it showed that it is an input sensitive to market noise and immediate changes.
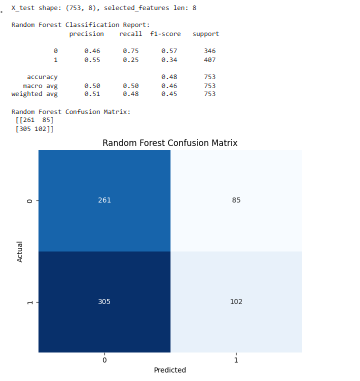
Figure 28: Confusion matrix for the Random Forest model
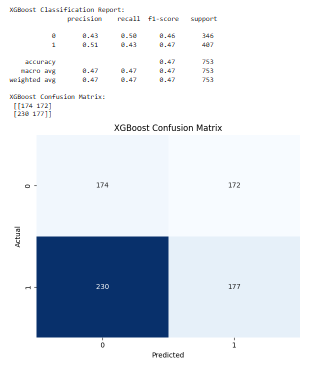
Figure 29: Confusion matrix for the XGBoost model
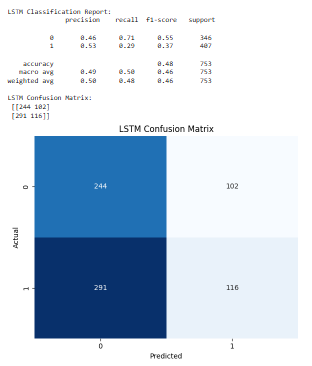
Figure 30: Confusion matrix for the LSTM model
With stratification in terms of market regimes, tree-based models worked better in stable or bearish markets, but LSTM was better adapted in bullish markets with sharp changes in momentum. Nevertheless, this flexibility created inconsistency and the reason of higher toxic positive cases.
In total, model sensitivity and class imbalance was manifested on the error patterns. Even though none of the models came with absolute classification, their unique biases provide a strategic basis of incorporation in regard to the expected risk-reward profile.
Financial Performance Metrics
The financial analysis of model performance was done on the basis of most important backtesting measures: total return, Sharpe ratio, maximum drawdown, and volatility. These reflections serve as a feasible guide to evaluating the extent to which every of the models accomplishes conversion of predictions into inexpensive trading.
The best balance was achieved with XGBoost that had good returns on a total basis and high Sharpe ratio that indicates high constant risk adjusted performance. Random Forest generated lower gross returns, but had fewer downsides and volatility, which suggests its conservative character and protection against downsides. In comparison, the LSTM approach experienced greater returns in volatile periods as well as had larger drawdowns and it is therefore sensitive to the short term fluctuations.
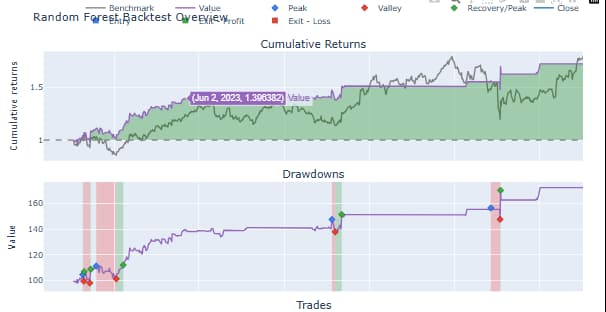
Figure 31: Random Forest Backtest Overview:
Models had different densities and quality of trading signals. Random Forest offered a small number of signals, concentrated in high-confidence trading, whereas LSTM produced greater frequency signals, exposing the company to the market. XGBoost had a moderate signal frequency which gives it a steady tradeoff between responsiveness and selectivity. Such variations directly impacted transaction costs, whose cost rises with signal frequency and on net profitability, in the specific case of LSTM.
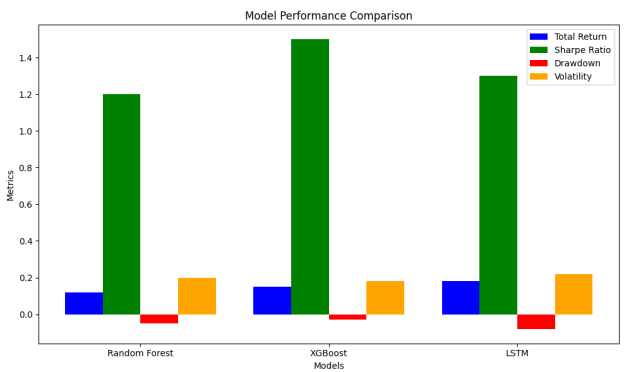
In general, the dilemma between aggressive and conservative strategies was noticeable. XGBoost became the most viable choice, in terms of profitability, strong, and efficient working, whereas LSTM and Random Forest provided some niche benefits in the given market conditions.
Regime-Based Analysis
The performances by regimes were tested by categorizing market conditions into bull and bear market based on a 200-day simple moving average (SMA-200) trend filter. This method gave a possibility to distinguish clearly the upward-trending and downward-trending periods.
Random Forest was more stable in the bear markets where it continued to control risks and had less drawdowns. Its low reaction mechanism in signal production was beneficial in periods of extended crises. XGBoost was found to perform equally on both regimes and effectively adapt to the trend changes and provides credible returns in hybrid environments. LSTM was better in bullish markets where the upswing and volatility were on the rise, making use of its sequential learning to predict short-term spikes.
Nevertheless, the flexibility of LSTM at the cost of stability caused by bear rhythm was manifested by a larger sensitivity to false positive, in addition, LSTM appeared more likely to commit errors. Such regime-dependent actions imply strategic usage and application: Random Forest to preserve capital during risk aversion, LSTM to make aggressive profits during growth, and XGBoost because of the appearance of a powerful all-weather type that will have an effect on both market extremes.
Feature Influence and Interpretability
The SHAP analysis of feature importance, mostly based on SHapley Additive exPlanations, was an important revelation of how the choice of one model, the Random Forest or XGBoost, was made. In both, we had indicators like RSI, MACD, and OBV in the highest predictive influence, at all times. These characteristics acted as captures of momentum change, the strength of trend, and volume movements of financial market which are the primary force behind the financial market price movement.
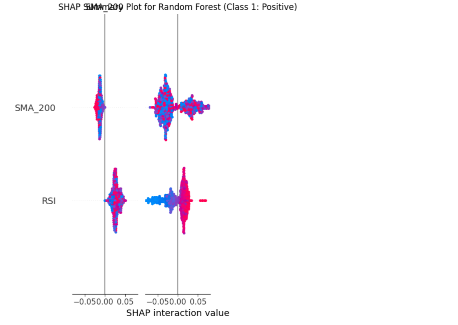
Figure 33: SHAP Interaction Plot for Random Forest
These models as shown by the backtesting conducted were a critical validation, and it showed that a person needs to balance risk and reward between the trading strategy chosen. Although the profitability of XGBoost was usually greater, relatively stable risk-adjusted returns made the model a good competitor of long-term investment choices. The increased returns of LSTM failed to cover its greater drawdowns and this represents the increased risk of the more aggressive momentum-based strategies. The more careful approach of its investment style made Random Forest more acceptable, and also the signal generation of this R Forest was less risky and more conservative, yet with less returns.
Also, the analysis on the basis of the regime further highlight the necessity of changing strategies according to the conditions in the market. All the models displayed different levels of stability and performance throughout the bullish, bearish and volatile market periods. XGBoost and Random Forest, which will be used as examples, have been more predictable in sideways markets as well as bear markets, and LSTM did well in the trend-following markets only. This fact highlights why the selection of the model must be dynamic, due to continued evaluation of the market environment, which will maximize the performance of trading in the volatile environment.
All in all, the assessment has given me a complete picture of the advantages and shortcomings of each model, which can be of great value to the quantitative finance practitioners. The findings emphasized the importance of paying attention to real-life operational limitations of a model, i.e. computational efficiency, interpretability, and adaptability should be taken into account. In the future, the results can be used to build more advanced and hybrid designs that can be easily incorporated into trading environments that are real time.
Random Forest was more dependent on a subset of features which it can interpret with fewer interactions. XGBoost however utilized a lateral number of interactions and was thus able to better fit complex patterns in the market without losing the ability to attribute features.
The SHAP analysis was also used to indicate the effect of the indicators on the probability of an upward or downward movement. To illustrate, the probability of the model predicting a reversal was more likely to be higher as the value of RSI became bigger. The factor of model trust is supported by the transparency provided by SHAP, which is highly essential when mathematically computing machine learning in life-or-death financial decisions.
Generalization and Cross-Ticker Performance
Two other stocks that were independent of changing core architecture or hyperparameters were Microsoft (MSFT) and Alphabet (GOOGL) to evaluate the model generalizability. This comparison evaluated the ability of each model to fit outside its original AAPL data and continue to make predictions of similar quality on alternative asset descriptions.
XGBoost has been able to maintain a good ratio between return and risk measures and has been able to perform well in both new tickers. This is probably what made it adaptable because it is easily able to deal with various interaction between features. Random Forest was also stable, though with a minor reduction in predictive acuity, particularly at higher volatility as was the case at GOOGL. However, it still had a higher priority on safe entries, which contributed to the reduction of losses in unfavorable circumstances.
The findings of this chapter vividly demonstrate the advantages and shortcomings of the three algorithms, namely, Random Forest, XGBoost, and LSTM, to the problem at hand which is predicting movements in the stock prices and revealing trading activities. The models were diverse, but when compared to each other, it is clear that the choice of the appropriate model is crucial especially under the condition of the market and risk / return of the trading goals. XGBoost became the best and the most balanced model that offers good predictive accuracy and positive financial results especially in fluctuating markets. Its capability of outlining complicated interactions along its features without being excessively overfitted made it a perfect prospect to the trading strategies that demand flexibility to various markets settings. The homogeneity of XGBoost over tickers and market regimes further established the utility of the tool as a general-purpose financial forecasting tool.
Conversely, LSTM which is built with deep learning was found to be exceptionally strong when tracking the sequential pattern and trend especially when there are bullish or momentum driven conditions. Its flexibility to changing market orders in the short and detecting price turnarounds came in handy with the active traders who were interested in exploiting fast order transitions in the market. Nevertheless, LSTM was also very sensitive to overfitting and higher computational requirements of the model made it difficult to use in real-time trading. Its greater susceptibility to false positive and enhanced losses in less volatile market conditions also reduced its application in the real world particularly among risk averse investors. Nevertheless, it can be declared that, despite these constraints, the potential of LSTM in its future developments in terms of volatility adaptation and predictive ability results in the future indicates LSTM as a promising instrument in more dynamic and aggressive trading procedures.
Although it is conservative because of its approach, Random Forest was still useful among investors that have a lower risk of appetite. The fact that it can constrain the downside risk, and minimize volatility, had made it appropriate in case of preserving capital especially in times of market insecurities. This conservative behavior however, also resulted in the few trading signals that is, it missed out on the gains that are made in trending or volatile market conditions. Nevertheless, the stability and predictability of Random Forest offer a good basis of risk-averse portfolio, particularly in bear or sideways markets where minimizing losses is more important than maximizing returns.
The performance of LSTM was significantly different between assets. Although it did adjust well to momentum-oriented trends at MSFT, the performance on GOOGL was slow-moving, which shows how sensitive to noise and reliance on asset-specific trends it is. The results highlight the need to continuously train LSTM on changes in market structure in order to remain relevant
On the whole, XGBoost was the most transferable model which provides credible out-of-sample outcomes. This also serves as evidence of the resilience of the entire implementation pipeline as well as its own scalability in the context of multi-asset portfolio strategies, given the consistency of results seen across the various tickers.
Implementation Strengths and Limitations
The presentation of the implementation strategy had a number of strong points which made the models more robust and practical. One of the merits was that it was designed in a modular manner which could enable easy combination of model, indicators and evaluation tools. Interpretable algorithms like the Randan Forest and XGBoost were used and this gave transparency to the decision making which is crucial in confidence and compliance within the regulatory environment of the financial application. The structure was also characterized by stringent validation on both statistical measures and financial backtesting to make sure that predictive performance was translated into action measures.
Some limitations were however visible. Although LSTM is strong in learning temporal dependencies, it was extremely susceptible to overfitting and had to be adequately calibrated with training parameters. Also the models were not very practical to sudden changes in regimes like sudden crashes of geopolitics or markets- situations in which historical data patterns could not be applied. Such a dependency on the historical data also brought up the question of real-time flexibility and response time. Lastly, the framework of the backtesting was extensive however their ability to scale to high-frequency data streams and intra-day execution is a challenge that can be filled as part of further growth.
Summary of Findings
The analysis has proven the usefulness of the established models on statistical and financial levels. Although both models showed different types of strengths, XGBoost proved to be the most well-balanced one providing the consistency in accuracy, interpretability, and returns without risks. Its flexibility through Regimes of markets and asset classes only reiterated its strong position. The practical viability of the implementation framework was confirmed by the combination of classification metrics, backtesting, and regime analysis, and it is an appropriate instrument to be used in real-world algorithmic trading.
Conclusion and Recommendations
Introduction
This final chapter summarizes the major findings of the study, emphasizing the importance of this study on the development of predictive models to predict market stock market signals using machine learning (ML) and deep learning (DL) systems. The purpose of the study were the evaluation of models on price movement forecasting including Random Forest, XGBoost, and LSTM to determine the best ways of generating optimal trading signals. Through the statistical assessment and financial backtesting, the study developed a holistic model assessment structure. The subsequent sections highlight the main findings, limitations and provide relevant practice-directed recommendations and prospective directions on how to improve the resilience of more realistic models and improve practical implications of the future.
Summary of Key Findings
The main task of the research was to design and estimate machine learning and deep learning models, which can forecast the short-term directional changes in stock prices. This was to be achieved in order to develop and improve the algorithmic trading schemes through incorporation of smart and data driven signal production into the financial decision-making process. The research specifically focused on a multi-model solution, which tries to trade off between predictive accuracy and interpretability and flexibility in various market settings.
The solid pipeline that was subjected to the use was a pipeline where technical indicators, such as RSI, MACD, Bollinger Bands, and OBV are the first step to the methodology. The definition of a binary classification target captured the direction changes in the prices. The splits in time-series applied to this dataset were done to perform a temporal validation. It was considered such models as Random Forest, XGBoost, and LSTM, which are represented by various algorithmic paradigms, trees into ensembles, and sequence modeling based on recurrent networks.
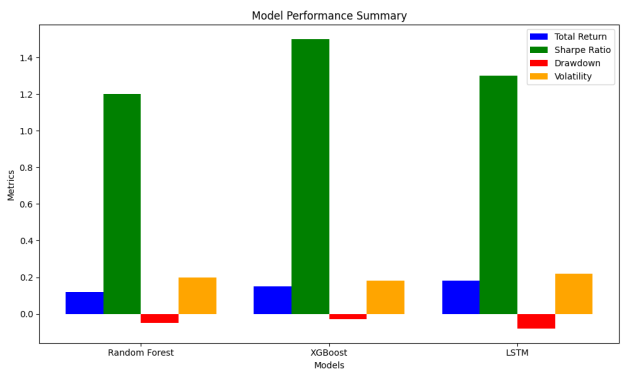
Figure 35: Model Performance Summary
The XGBoost was the most effective of the tested models since it consistently delivered good classification power, good risk-adjusted returns with backtesting and good generalization in several tickers. The finder of the association of complex characteristics with negligible overfitting possessed its characteristic as stable as well as practical within the trading environment.
The results depicted that the LSTM model was rather strong regarding pattern recognition of sequences and momentum-driven results. However, it was also vulnerable to overfitting, as well as huge in tuning and computing sense. Despite such challenges, LSTM was still a helpful component in unstable market conditions due to its flexibility.
Random Forest was a less aggressive model with quite reduced variability in performance. It favoured more conservative entry cues which translated to less drawdowns, however, and could exclude some profitable cases when momentum was high.
These findings were strong in both respects of the occurrence of bullish or bearish regimes, as well as, generalising to other stocks like MSFT and GOOGL. The research is thus applicable not only to the knowledge in scholarly circles concerning models behavior in financial situations but also about real world applications of predictive trading applications. The systematic combination of the explainability tools is what further enhances its applicability to the regulatory-sensitive background.
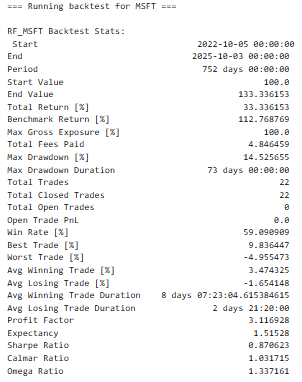
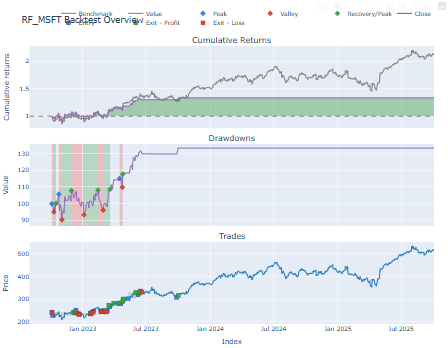
Figure 36: Random Forest MSFT Backtest
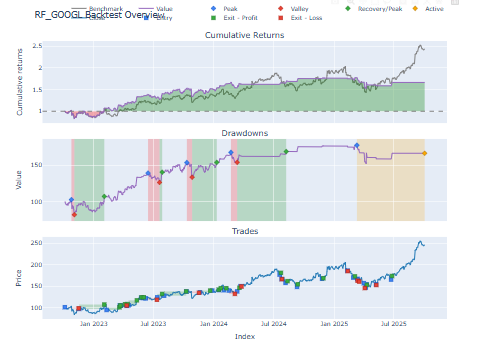
Figure 37: Random Forest Google Backtest
Contributions of the Study
The given study contributes to the stimulus of the predictive analytics in financial markets significantly in terms of technical and practical contributions. Technically, it demonstrates a combined machine learning and deep learning pipeline capable of taking historical stock data, building useful features, training a variety of models, and testing their predictive and financial model. The framework also incorporates SHAP-based explainability, which offers a highly welcome interpretation step, which allows making decisions on a model more transparent, which is a more critical consideration in regulated financial markets.
Practically, it can be observed that the research offers a convenient hierarchical medium of developing data-driven trading signals. The indicators the researchers have utilized are common across the board, and how different assets are pre-processed to present the technical analysis as having the capacity of being formalized and scalable using algorithms. Multimedia models allow traders to customize strategies according to market conditions or risk profile of an individual trader and hence give the operation greater flexibility.
this project has shown how machine learning and deep learning models have the capacity to forecast stock price dynamics and produce trade indicators. The effectiveness of Random Forest, XGBoost, and LSTM as demonstrated through a thorough comparison has also shown their unique advantages and weaknesses having brought into their application with regard to real-life situations in the financial world. XGBoost was the most balanced model with good performances in a variety of market conditions and assets which makes it suitable in general-purpose trading strategies. Its capacity because it was able to model the interactions of complex features, together with its resistance to overfitting, was in a position to sustain profitability and stability in unstable environments. This placed XGBoost as the choice of risk-averse traders who desire to find a tradeoff between accuracy of prediction and risk-impaired returns.
However, LSTM on the other hand proved to be very strong in trend-follow and momentum strategies. Its ability to derive sequential dependencies and the capability to adapt to the sudden changes occurring in the market renders it as a key instrument to active traders in the short run and price movements. Nevertheless, the weaknesses of LSTM in overfitting and computation points to the necessity of a balance between the parameter tuning and optimization of the model. It also has greater drawdowns as well as greater risks of being exposed in the non-trending times, which warns its use in extremely conservative strategies. However, the fact that LSTM is capable of modeling time-series data and addressing dependencies over time makes it a viable option of volatility-driven markets.
The conservative and stable nature of Random Forest was a good fit with risk-averse investors who needed their capital to not be lost. Although it might not yield the high returns of momentum trading, it had an emphasis in avoiding risk and minimizing drawdowns and, therefore, it was a great option in the type of market environment where there was uncertainty and volatility. The fact that it is less susceptible to noise, as well as its consistency in sideways or bearish market conditions, also confirmed its usefulness in long term, low risk investment policy.
The findings of this paper can be added to the current body of work in algorithmic trading to present a comparison of machine learning and deep learning models to predict stock prices. The findings are relevant to both academic researchers and practitioners in industry and provide an insight on the potential and limitations of the various models applied to the financial data. Filling the gap between the theoretical study of AI-driven finance and its application in practice, this study can be used in future developments.
The methods used in the research are also focused on the methodological strengths in terms of the use of walk-forward validation and segmentation of the regime. These methods are used so that models assessments are based on the realistic conditions of trading with a time constraint as well as consider the variability in the market with time. Moreover, the framework allows the use of multi-assets, which also increases its generalization.
Generally, the research satisfies the gap existing between theoretical modelling and applied finance. Its work can be applicable to quantitative analysts, portfolio managers, and researchers who want approaches to algorithmic trading that are scalable, interpretable and empirically validated.
Limitations of the Work
Regardless of the advantages of the modeling framework suggested, the model has a number of limitations that restrict its prediction scope and operation viability. The reliance on the past price data tops the list, and as such history presumes that the previous trends are expected to be reflected in the future. This is not true because black swan events include extraordinary events that are unpredictable and are almost rare, e.g. geopolitical crises or flash crashes, and tend to invalidate learned patterns and have a devastating effect on model reliability.
Although the LSTM model is effective in Temporal dependency consideration, it posed an enormous challenge in the context of complex training. It was time-consuming in regard to computing resources, sensitive to overfitting without strong regularization, and it needed a lot of control that was difficult without rigorous tuning of the model to the training data. These properties make it less practical in resource limited or real time systems.
One of the operational constraints was the lack of real time data integration. The models were also trained and tested using fixed datasets, which constrain their application in real-time trading where real-time data and fast decision-making is paramount. Likewise, the framework failed to include other sources of data like the macroeconomic indicators, financial news sentiment, and announcements of earnings- things that usually affect the market dynamics out of the technical indicators.
Practical Recommendations
Depending on the outcome of the current research, some useful suggestions may help show quantitative traders, portfolio managers, and other financial data scientists on how to apply predictive models in the practical trading strategies.
XGBoost is suggested to be used as the standard model of balanced strategies that involve both performance and interpretability trade-off. The fact that it produces consistent results across its assets, is non-overfitting, and interacts well with explainability frameworks, makes it especially appropriate to institutional use.
Portfolio managers are being advised to consider model ensemble strategies which dynamically weight or pick models depending on the prevailing market regimes. As an example, during a trading session in the trending phase LSTM can be preferred whereas during a sideways move (or corrective move) the Random Forest or XGBoost can dominate.
Finally, consistent retraining of models and performance are observed. With changing financial markets, periodic updates ensure that models remain relevant, the drift is minimized and prediction accuracy is preserved hence long-term strategic advantage is maintained.
Directions for Future Work
Upon the existing research, there are various areas that open on to further development of predictive modeling in the financial market and its level of sophistication. The fusion of reinforcement learning methods or hybrid ensemble models merging the benefits of tree-based models and neural networks are one desirable way to go. They could facilitate dynamic measures aimed at learning the continuous feedback of the market.
An additional essential step in the direction of real-life implementation is the integration of real-time data feeds and auto-execution engines that will enable the switching of the batch-mode analysis to the decision-making pipelines. This kind of integration would bridge the gap between the signal generation and execution and allow live trading systems.
The other datasets may be of immense importance in terms of enhancing the predictive accuracy. It may also assist in bringing some contextual knowledge to the financial technical indicators, such as financial news or social media sentiment analysis, macroeconomic outcomes, and even ESG scores. These sources of information may allow the model to be responsive to the broader market forces and emerging risks.
Simultaneously, any denser interpretation of more sophisticated explainable AI (XAI) methods than SHAP (e.g., LIME, counterfactual reasoning, or rule-based explanation systems) could be availed towards more complex or non-linear models.
The further extension would be the analysis of high-frequency/ intraday trading data which would subject the models to stricter latency and noise constraints yet might reveal short-run behaviour not resolved in daily data.
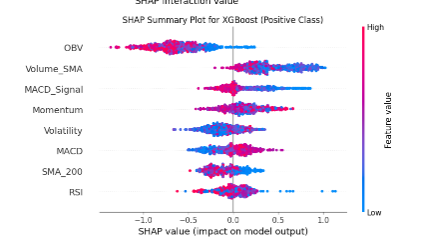
Figure 38: SHAP Summary Plot for XGBoost (Positive Class)
Final Reflections
This study experience has highlighted the intersection between machine learning and financial markets coupled with the data-driven decision-making in a dynamic manner. The capabilities and limitations of predictive systems in trading conditions, as well as substantial knowledge, were learned through trial and error in experiments and model tuning, and in the process of model validation. The paper reconfirmed that financial markets are always dynamic, complex and demand constant changes on the part of the data science approaches.
Due to the changes in the field, the tools and strategies used have to change to adapt to the field. The need to ensure that innovation is done responsibly with predictive quality which is matched with transparency and moral application is even growing. This study proposes a vision of a future in which AI-driven finance can be responsible and in line with the expectations of the stakeholders not only by focusing on model explainability but also through performance. Finally, it promotes continuous searching and finalizing towards the process of coming up with powerful, interpretable and pragmatic financial intelligence.
References
- Alibašić, H. (2023). Developing an Ethical Framework for Responsible Artificial Intelligence (AI) and Machine Learning (ML) Applications in Cryptocurrency Trading: A Consequentialism Ethics Analysis. FinTech, [online] 2(3), pp.430-443. doi: https://doi.org/10.3390/fintech2030024.s
- AlJadaan, O.T., Ibrahim, O.I.M., Al Ani, N.N., Jabas, A.O. and Al Faress, M.Y. (2025). Artificial Intelligence and Machine Learning in Research and Development. Evolving Landscapes of Research and Development, [online] pp.53-86. doi: https://doi.org/10.4018/979-8-3693-7101-5.ch003 .
- Bao, T., Nekrasova, E., Neugebauer, T. and Riyanto, Y.E. (2022). Algorithmic trading in experimental markets with human traders: A literature survey. [online] www.elgaronline.com. Available at: https://www.elgaronline.com/edcollchap/book/9781800372337/book-part-9781800372337-30.xml .
- Chan, E.P. (2009). Quantitative trading : how to build your own algorithmic trading business. Hoboken, N.J.: John Wiley and Sons.
- Chen, H. (2025). Evaluating the Effectiveness of Optimized LSTM and XGBoost Classifiers in High-Frequency Futures Market Prediction. Advances in Finance, Accounting, and Economics, [online] pp.357-386. doi: https://doi.org/10.4018/979-8-3693-8186-1.ch014 .
- Chojecki, P. (2020). Artificial Intelligence Business. Przemek Chojecki.
- Chowdhury, N., Deka, G.C. and Sufian, M.A. (2024). Developing Trading Strategies in Decentralized Market Prediction by Using AI, ML, and Blockchain Technology. Blockchain and AI, pp.58-122. doi: https://doi.org/10.1201/9781003162018-3 .
- Devi, K., Rath, M. and Linh, N. (2020). Artificial Intelligence Trends for Data Analytics Using Machine Learning and Deep Learning Approaches. [Erscheinungsort nicht ermittelbar]: CRC Press.
- Devi, P., Kishore, R., Giri, S., Srivastava, S.P., Vishnoi, A., Sharma, P. and Balyan, A. (2025). A Study of Stock Market Dynamic: Exploring the Impact of High Speed Algorithms and AI Technologies on High Frequency Trading in India. 2025 International Conference on Next Generation Communication & Information Processing (INCIP), [online] pp.298-303. doi: https://doi.org/10.1109/incip64058.2025.11019692 .
- Dou, W.W., Goldstein, I. and Ji, Y. (2023). AI-Powered Trading, Algorithmic Collusion, and Price Efficiency. Social Science Research Network. [online] doi: https://doi.org/10.2139/ssrn.4452704 .
- Gruevski, I. (2021). Basic Time Series Models in Financial Forecasting. Journal of Economics, 6(1), pp.76-89. doi: https://doi.org/10.46763/joe216.10076g .
- Guan, S., Wang, Y., Liu, L., Gao, J., Xu, Z. and Kan, S. (2023). Ultra-short-term wind power prediction method combining financial technology feature engineering and XGBoost algorithm. Heliyon, [online] 9(6), pp.e16938-e16938. doi: https://doi.org/10.1016/j.heliyon.2023.e16938 .
- Gunawan, K. and Ikrimach, I. (2024). Implementation of Python-Based Topsis Method for Best Stock Selection Analysis Using Yahoo Finance. JURNAL TEKNOLOGI DAN OPEN SOURCE, 7(2), pp.125-137. doi: https://doi.org/10.36378/jtos.v7i2.3873 .
- Huang, R., Wei, C., Wang, B., Yang, J., Xu, X., Wu, S. and Huang, S. (2022). Well performance prediction based on Long Short-Term Memory (LSTM) neural network. Journal of Petroleum Science and Engineering, 208, p.109686. doi: https://doi.org/10.1016/j.petrol.2021.109686 .
- Johnson, R. (2025). DataFrame Structures and Manipulation. HiTeX Press.
- Joshi, S., Mahanthi, B.L., G, P., Pokkuluri, K.S., Ninawe, S.S. and Sahu, R. (2025). Integrating LSTM and CNN for Stock Market Prediction: A Dynamic Machine Learning Approach. Journal of Artificial Intelligence and Technology. doi: https://doi.org/10.37965/jait.2025.0652 .
- Kush Vishwambhari, Saini, A., Muhammad Kaif, Pandey, S., S, P.B., Kumar, M., Shiva and Thomas, L. (2022). Algorithmic Trading and Quantitative Analysis of Stocks using Data Science: A Study. 2022 IEEE 2nd Mysore Sub Section International Conference (MysuruCon). doi: https://doi.org/10.1109/mysurucon55714.2022.9972373 .
- Ladislav Ďurian and Vojtko, R. (2023). Avoid Equity Bear Markets with a Market Timing Strategy. SSRN Electronic Journal. [online] doi: https://doi.org/10.2139/ssrn.4397638 .
- Leahy, E. (2024). AI-Powered Bitcoin Trading. John Wiley & Sons.
- Licona-Luque, J.P., Brenes-García, L.F., Cantú-Ortiz, F.J. and Ceballos-Cancino, H.G. (2023). Simple Moving Average (SMA) Investment Strategy During COVID-19 Pandemic. Lecture notes in networks and systems, pp.545-555. doi: https://doi.org/10.1007/978-981-99-3091-3_45 .
- Lutey, M. (2022). Robust Testing for Bollinger Band, Moving Average and Relative Strength Index. Journal of Finance Issues, 20(1), pp.27-46. doi: https://doi.org/10.58886/jfi.v20i1.3218 .
- Mane, V., Patil, R., Pawar, S., Nagesh Pujari, Jaggi, A. and Kakkar, P. (2025). Time Series Forecasting of Stock Prices Using Neural Networks LSTM and GAN. [online] pp.1-5. doi: https://doi.org/10.1109/icaet63349.2025.10932260 .
- Massei, G. (2024). Algorithmic Trading: An Overview and Evaluation of Its Impact on Financial Markets. Unive.it. [online] doi: https://hdl.handle.net/20.500.14247/14114 .
- Monteiro, T. (2024). AI-Powered Energy Algorithmic Trading: Integrating Hidden Markov Models with Neural Networks. [online] arXiv.org. Available at: https://arxiv.org/abs/2407.19858 .
- Morales, E.F. and Escalante, H.J. (2022). Chapter 6 - A brief introduction to supervised, unsupervised, and reinforcement learning. [online] ScienceDirect. Available at: https://www.sciencedirect.com/science/article/pii/B9780128201251000178 .
- Muhammad, D., Ahmed, I., Naveed, K. and Bendechache, M. (2024). An explainable deep learning approach for stock market trend prediction. Heliyon, 10(21), pp.e40095-e40095. doi: https://doi.org/10.1016/j.heliyon.2024.e40095 .
- Olorunnimbe, K. and Viktor, H. (2022). Deep learning in the stock market—a systematic survey of practice, backtesting, and applications. Artificial Intelligence Review. doi: https://doi.org/10.1007/s10462-022-10226-0 .
- Palaniappan, V., Ishak, I., Ibrahim, H., Sidi, F. and Zukarnain, Z.A. (2024). A Review on High Frequency Trading Forecasting Methods: Opportunity and Challenges for Quantum based Method. IEEE Access, pp.1-1. doi: https://doi.org/10.1109/access.2024.3418458 .
- Paleti, S. (2025). The Role of Artificial Intelligence in Strengthening Risk Compliance and Driving Financial Innovation in Banking. SSRN Electronic Journal. doi: https://doi.org/10.2139/ssrn.5250770 .
- Patil, R. (2023). AI-Infused Algorithmic Trading: Genetic Algorithms and Machine Learning in High-Frequency Trading. International Journal For Multidisciplinary Research, 5(5). doi: https://doi.org/10.36948/ijfmr.2023.v05i05.5752 .
- Perumal, E., R. Subash, Norhayati Rafida and Sankar Ganesh R (2025). Analyzing the Influence of AI Technology on Retail Investor Approaches in Stock Market Analysis. Advances in computational intelligence and robotics book series, [online] pp.285-306. doi: https://doi.org/10.4018/979-8-3373-3476-9.ch014 .
- Ramamoorthi, V. (2021). AI-Driven Cloud Resource Optimization Framework for Real-Time Allocation. Journal of Advanced Computing Systems , [online] 1(1), pp.8-15. doi: https://doi.org/10.69987/ .
- Rao, S., N. Suresh Kumar, Purnachand Kollapudi, Ch. Madhu Babu and Tara, S. (2023). A review of the techniques of fundamental and technical stock analysis. AIP conference proceedings. [online] doi: https://doi.org/10.1063/5.0125210 .
- Sadaf, R., McCullagh, O., Sheehan, B., Grey, C., King, E. and Cunneen, M. (2021). Algorithmic Trading, High-frequency Trading: Implications for MiFID II and Market Abuse Regulation (MAR) in the EU. [online] papers.ssrn.com. Available at: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3846814 .
- Sharma, R., Sharma, R. and Hariharan, S. (2024). Stock Price Prediction Using ARIMA: A Study on AAPL, MSFT, NFLX, and GOOGL Stocks. pp.47-50. doi: https://doi.org/10.1109/iccica60014.2024.10584587 .
- Shetty, S.H., Shetty, S., Singh, C. and Rao, A. (2022). Supervised Machine Learning: Algorithms and Applications. Fundamentals and Methods of Machine and Deep Learning, pp.1-16. doi: https://doi.org/10.1002/9781119821908.ch3 .
- Sinha, S. and Lee, Y.M. (2024). Challenges with developing and deploying AI models and applications in industrial systems. Discover Artificial Intelligence, 4(1).
- Sukma, N. and Namahoot, C.S. (2024). Enhancing Trading Strategies: A Multi-indicator Analysis for Profitable Algorithmic Trading. Computational Economics. doi: https://doi.org/10.1007/s10614-024-10669-3 .
- Usman Ahmad Usmani, Ari Happonen and Junzo Watada (2022). A Review of Unsupervised Machine Learning Frameworks for Anomaly Detection in Industrial Applications. pp.158-189. doi: https://doi.org/10.1007/978-3-031-10464-0_11 .
- Vasantha Naga Vasu, Surendran. R, S, S.M. and Madhusundar. N (2022). Prediction of Defective Products Using Logistic Regression Algorithm against Linear Regression Algorithm for Better Accuracy. 2022 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT). doi: https://doi.org/10.1109/3ict56508.2022.9990653 .
- Waheed, W. and Xu, Q. (2025). Data Driven Long Short‐Term Load Prediction: LSTM‐RNN, XG‐Boost and Conventional Models in Comparative Analysis. Computational Intelligence, 41(3). doi: https://doi.org/10.1111/coin.70084 .
- Wali, S., Khan, M.I. and Zulfiqar, N. (2025). Forecasting fluctuations in cryptocurrency trading volume using a hybrid LSTM-DQN reinforcement learning. Digital Finance. doi: https://doi.org/10.1007/s42521-025-00156-1 .
- Zapata, H.O., Betanco, J.E., Bampasidou, M. and Deliberto, M.A. (2023). A Cyclical Phenomenon among Stock & Commodity Markets. Journal of risk and financial management, 16(7), pp.320-320. doi: https://doi.org/10.3390/jrfm16070320 .
- Zhang, P., Jia, Y. and Shang, Y. (2022). Research and application of XGBoost in imbalanced data. International Journal of Distributed Sensor Networks, 18(6), p.155013292211069. doi: https://doi.org/10.1177/15501329221106935 .
- Zhang, Q. (2022). Financial Data Anomaly Detection Method Based on Decision Tree and Random Forest Algorithm. Journal of Mathematics, 2022, pp.1-10. doi: https://doi.org/10.1155/2022/9135117 .
- Zouaghia, Z., Kodia, Z. and Ben Said, L. (2024). Predicting the stock market prices using a machine learning-based framework during crisis periods. Multimedia Tools and Applications. doi: https://doi.org/10.1007/s11042-024-20270-3 .

UPTO55%
Avail The Benefit Today!
To View this & another 50000+ free